(Interestingly, this is the first time arXiV has declined a submission from me. I would give the editors kudos for finally taking their role seriously if it wasn’t because I suspect this is simply the result of a poor algorithmic decision that detected I had used AI assistance in writing the paper and violated a rule of disclosing such use. More discussion on this topic in this LinkedIn post and the comments.)
Cite as
@misc{amatriain2024llmhallucinations,
title={Measuring and Mitigating Hallucinations in Large Language Models: A Multifaceted Approach},
author={Xavier Amatriain},
year={2024},
}
Abstract
The advent of Large Language Models (LLMs) has ushered in a new era of possibilities in artificial intelligence, yet it has also introduced the challenge of hallucinations—instances where models generate misleading or unfounded content. This paper delves into the multifaceted nature of hallucinations within LLMs, exploring their origins, manifestations, and the underlying mechanics that contribute to their occurrence. We present a comprehensive overview of current strategies and methodologies for mitigating hallucinations, ranging from advanced prompting techniques and model selection to configuration adjustments and alignment with human preferences. Through a synthesis of recent research and innovative practices, we highlight the effectiveness of these approaches in reducing the prevalence and impact of hallucinations. Despite the inherent challenges, the paper underscores the dynamic landscape of AI research and the potential for significant advancements in minimizing hallucinations in LLMs, thereby enhancing their reliability and applicability across diverse domains. Our discussion aims to provide researchers, practitioners, and stakeholders with insights and tools to navigate the complexities of hallucinations in LLMs, contributing to the ongoing development of more accurate and trustworthy AI systems.
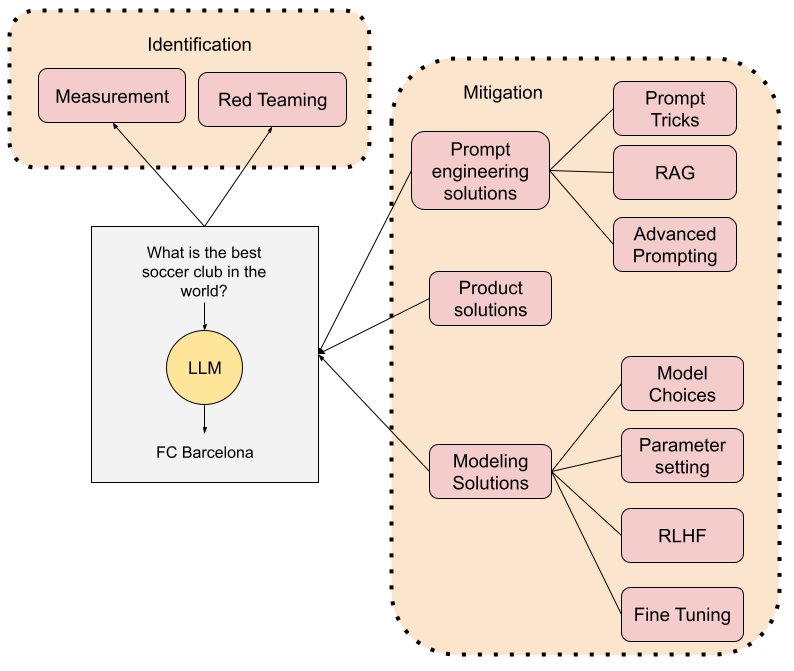 Mitigating hallucinations requires a multifaceted approach
Mitigating hallucinations requires a multifaceted approach