Ten years ago, we published a post in the Netflix tech blog explaining our three-tier architectural approach to building recommender systems (see below). A lot has happened in the last 10 years in the recommender systems space for sure. That’s why, when a few months back I designed a Recsys course for Sphere, I thought it would be a great opportunity to revisit the blueprint.
In this blog post I summarize 4 existing architectural blueprints, and present a new one that, in my opinion, encompasses all the previous ones.
At a very high-level, any recommender system has items to score and/or rank, and a machine learned model that does that. This model needs to be trained on some data, which is obtained from the service where the recommender operates in some form of feedback loop. The architectural blueprints that we will see below connect those components (and others) in a general way while incorporating some best practices and guidelines.
The Netflix three tier architecture
In our post ten years ago, we focused on clearly distinguishing the components that can be executed offline (i.e. not when the recommendations need to be served but rather e.g. once a day), those that need to be computed online (i.e. when the user visits the site and the recommendation is being served) and those somewhere in the middle called nearline (i.e. components that are executed when the user visits the site, but do not need to be served in real-time). At that time, and still today in many cases, most of the big data training of the algorithm was performed offline using systems such as Hadoop or Spark. The nearline layer included things like filtering in response to user events, but also some retraining capabilities such as e.g. folding-in and incremental matrix factorization training (see here for a practical introduction to the topic).
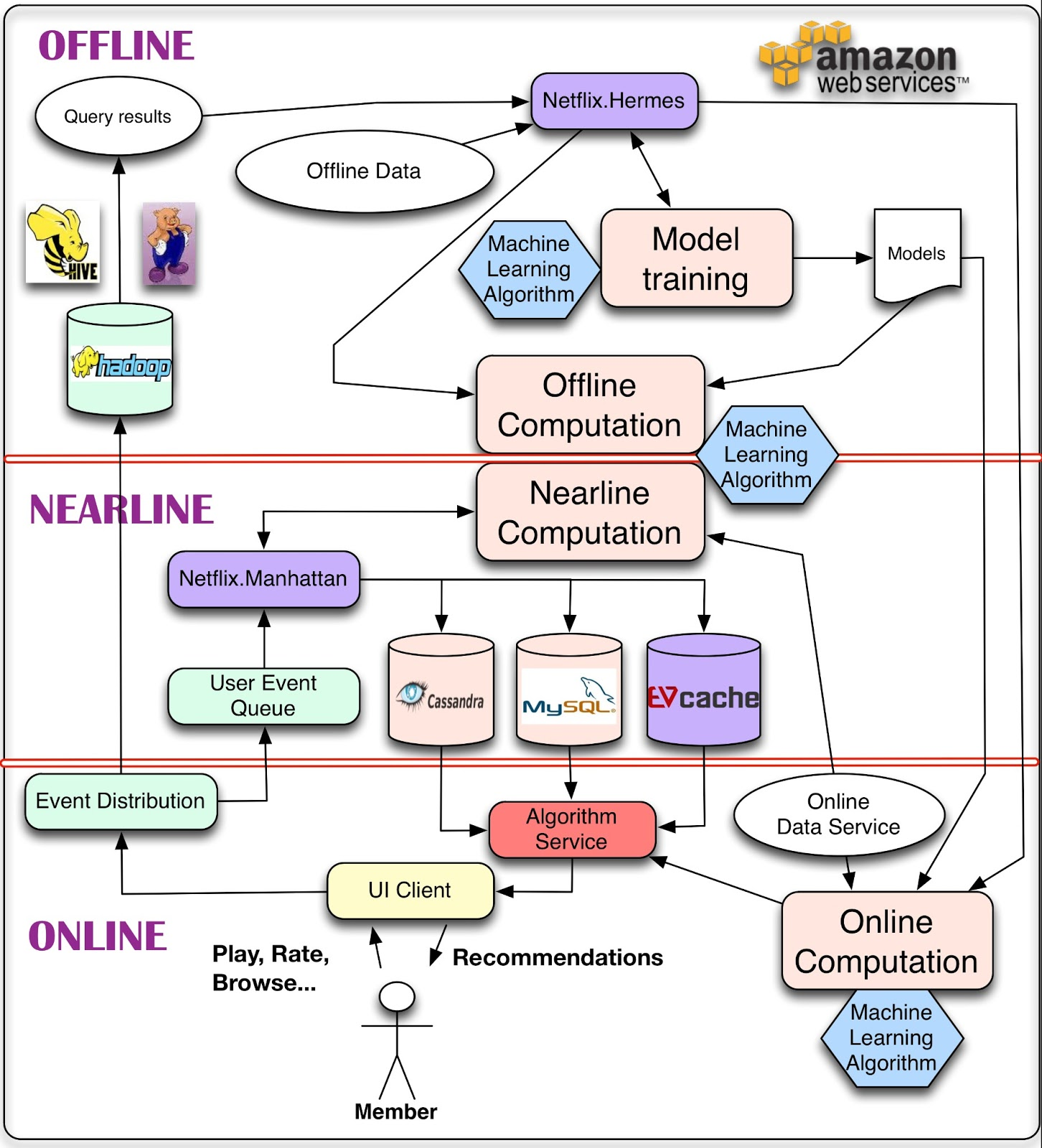
Ten years ago I felt like this architecture was state of the art. A lot of things have happened since then in the machine learning world, but this three tiered approach is still pretty relevant. Let’s fast forward.
Eugene Yan’s 2 x 2 blueprint
Amazon’s Eugene Yan does an amazing job of compiling many industry posts in his june 2021 post. He cites and describes systems from Alibaba, Facebook, JD, Doordash, and LinkedIn. If you are interested in this space, you should totally read his post (and the rest of his blog btw). After this amazing compilation and distillation work, he presents the following 2x2 blueprint:
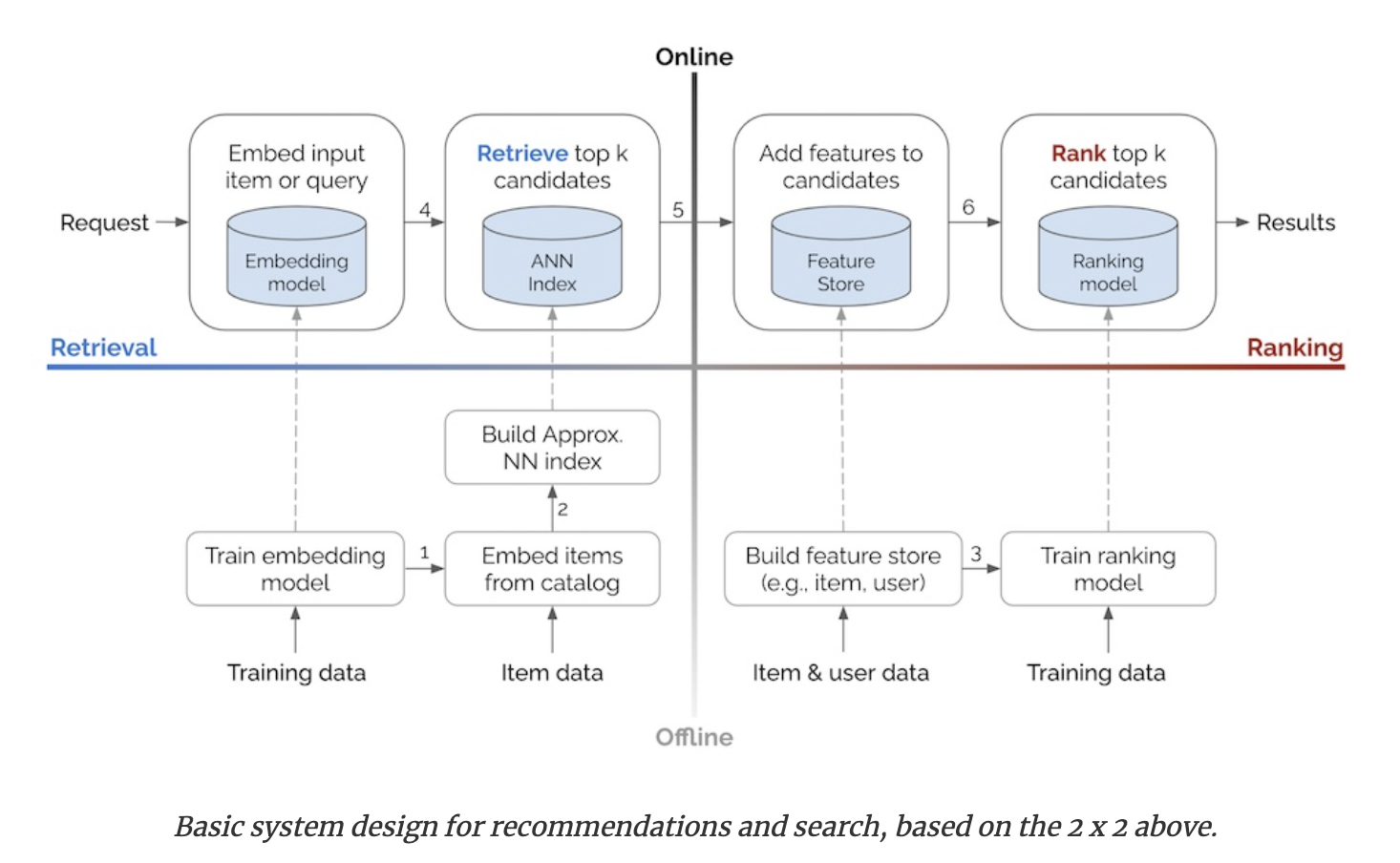
There are a few things worth noting here. First off, as opposed to our previous blueprint, this one only distinguishes between online and offline. That being said, the “Build Approx. NN index” is close to the boundary, so almost could be considered nearline. Second, this blueprint very much focuses on the latest trend of neural network and embedding-based recommender systems, particularly on the retrieval side of things. While that does exclude “older” approaches, it is a fair assumption since most recommender systems nowadays have replaced the matrix factorization approaches with newer embedding based dimensionality reduction approaches.
Finally, and very importantly, what’s with those “retrieval” components? Why weren’t they even present in our original blueprint? I am glad you asked. It turns out that at Netflix the catalog of items was so small that we did not have to select a subset for ranking. We could literally rank the whole catalog for every member. However, in most other situations, as I quickly learned at Quora, you cannot rank all items for all users all the time. Therefore, this two phase approach where you first select candidates using some retrieval approach, and then you rank them, is pretty much general purpose.
Nvidia’s 4 stage blueprint
A few months later, Even and Karl from NVidia’s Merlin team published a new architectural blueprint that they acknowledge extended Eugene’s.
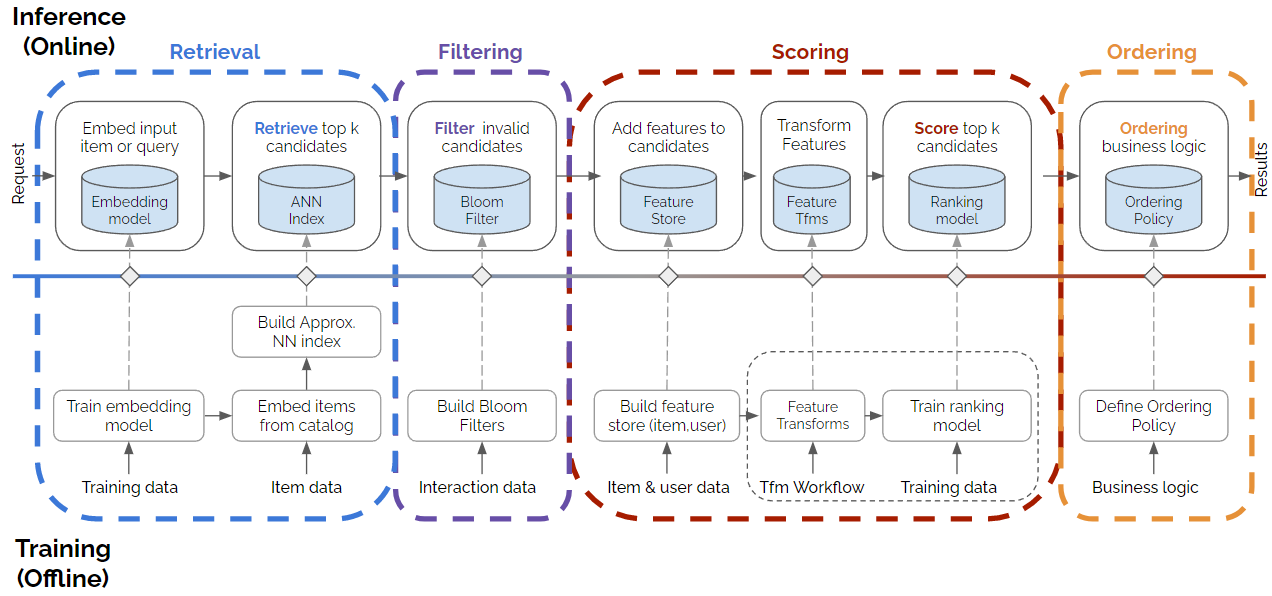
Indeed, it is clear that this is an extension of the previous blueprint where they added a filtering step, and they decomposed ranking into scoring and ordering. While I think those two changes make sense, I do think the way they are named and described is confusing, and not general purpose enough. The key aspect to keep in mind is that both before and after the machine learning model is applied (either for scoring or ranking), many systems apply business logic or some other kind of logic for filtering or re-ranking. However, filtering can also be done after scoring or even ranking. And, as mentioned, ranking or ordering is not necessarily done following some business logic. For example, a multi-armed bandit approach can be used at this stage to learn the optimal exploration/exploitation strategy.
Fennel.ai’s 8 stage blueprint
Finally, my friends at Fennel.ai recently published a three posts series describing an 8-stage recommender systems architecture.
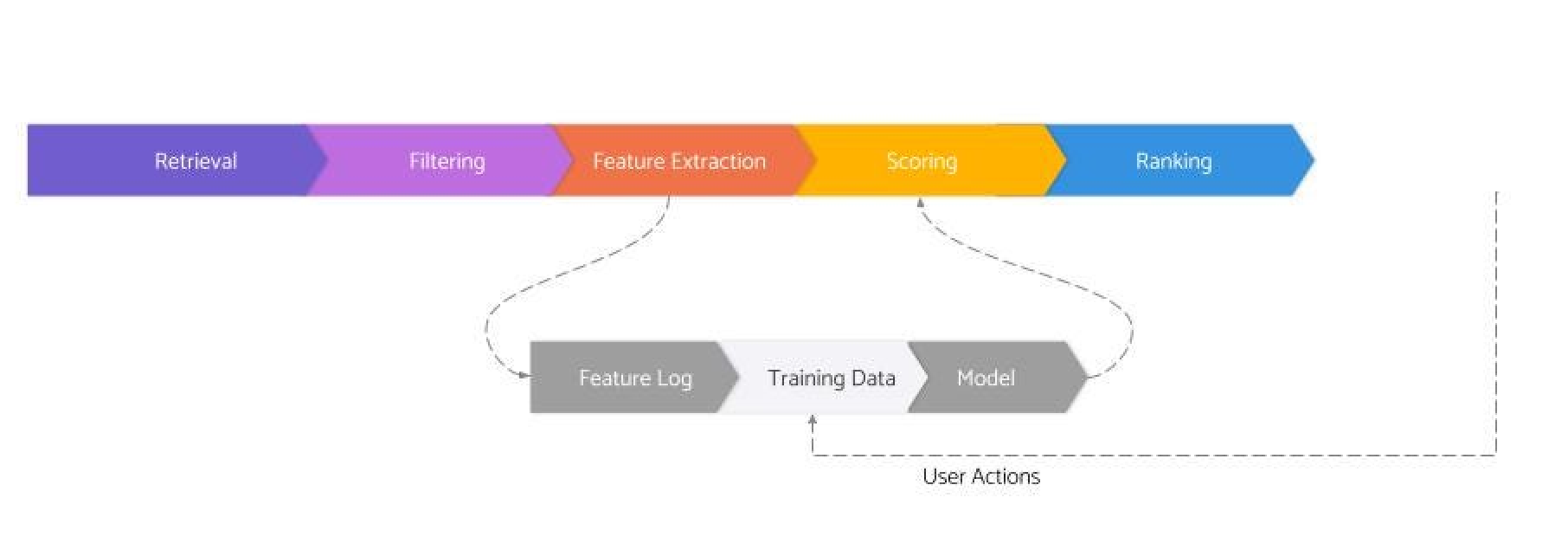
While this might seem simpler than the previous two, there are few things I like. First off, it is more generic than the other two, which are very much focused on neural network/embedding-based systems. Second, and importantly, their blueprint highlights the importance of the feedback loop where the data generated by the system flows back into the training data.
My latest proposal
Given all the above, and in the context of a course on recommender systems that I recently prepared with Deepak Agarwal, I am proposing the new expanded blueprint below:
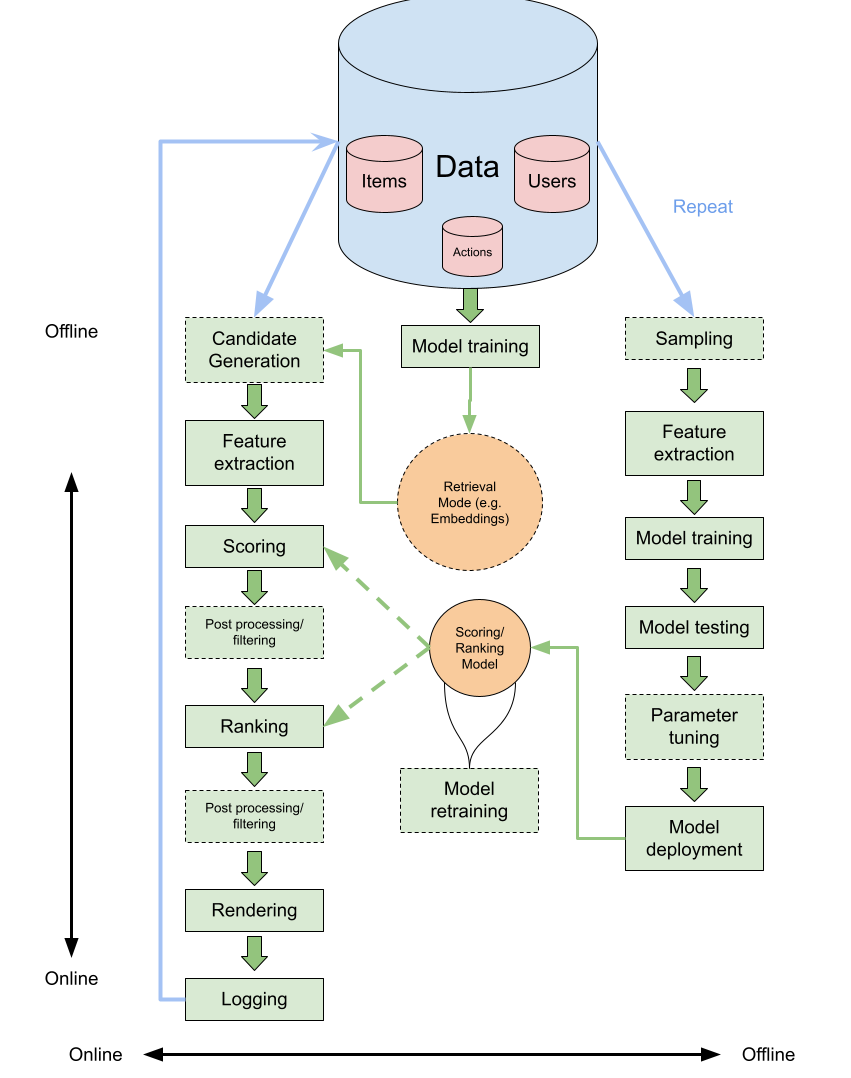
I am not going to go into the details of all the components in this post, and might do so in a second part if there is enough interest, but I will point out some important aspects and differences when compared to some of the previous ones:
- This blueprint highlights the central role of data, and the feedback loop in recommender systems
- It includes two potential ML models: one for retrieval (e.g. embeddings) and the other one for scoring or ranking.
- It does not prescribe components having to be offline, online, or nearline but rather introduces the notion that some components are more likely to be online while others are more likely to be offline. This is important given the trend of more and more components transitioning to being more online in modern recommender systems.
- It includes several components that are optional (dashed lines). Those include even candidate selection. While that component is extremely important in services with large catalogs it is not necessary in others like Netflix.
- Among those optional components, there are two post-processing/filtering components both after scoring and after ranking. To be clear, scoring and ranking are not necessarily two separate components since an ML model can be optimized directly for ranking, and that is why scoring is also optional. But it is important to note that post-processing and/or filtering can be introduced at almost any step (e.g. it could also be included after candidate generation).
Let me know what you think about this new proposal and whether you would be interested in a more detailed follow up.
References
- System Architectures for Personalization and Recommendation(2013)
- Deep Neural Networks for YouTube Recommendations (2016)
- Wide & Deep Learning for Recommender Systems (2016)
- Practical Lessons for Building Machine Learning Models in Production (2017)
- Related Pins at Pinterest: The Evolution of a Real-World Recommender System (2017)
- Powered by AI: Instagram’s Explore recommender system (2019)
- Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba (2018)
- System Design for Recommendations and Search (2021)
- Evolving the Best Sort for Reddit’s Home Feed (2021)
- On YouTube’s recommendation system (2021)
- Recommender Systems, Not Just Recommender Models (2022)