In the landscape of Generative AI (GenAI), we often find ourselves amazed at the rapidity and scale of advancements. GPT-4 stands as a shining example, pushing the boundaries of linguistic understanding and generation. Yet, as we move forward, a compelling new horizon emerges: the Multimodal Generative AI Revolution. By melding GPT-4’s textual capabilities with multimodality—integrating diverse data types such as images, voice, and video—we’re not just opening a door, but unleashing a tidal wave of transformative potential that promises to redefine our digital experiences.
Four illustrative examplesPermalink
The conceptual promise of the Multimodal Generative AI Revolution is undeniably thrilling, but it’s in the practical applications that its true value becomes tangible. As we bridge the realms of text, image, voice, and more, we begin to see direct impacts on our daily lives and interactions. Let’s delve into three illustrative examples that showcase how GPT-4’s multimodal capabilities are set to redefine our experience:
Unveiling the Mystery Box: We’ve all been there, receiving a package without any inkling of what lies inside. With GPT-4, by simply interpreting the SKU numbers on the label, it can instantly elucidate the contents of the box. It doesn’t just stop at identification. The AI could provide details, reviews, or even suggest complementary products based on the identified item.

Calorie Counting Made Simple: Picture this - you’re about to dig into a plate of bananas but wonder about the calorie count. Snap a photo, and GPT-4 will not only tell you the calories in those three bananas but also suggest how much you should walk to burn those off. It’s like having a nutritionist and personal trainer in your pocket!
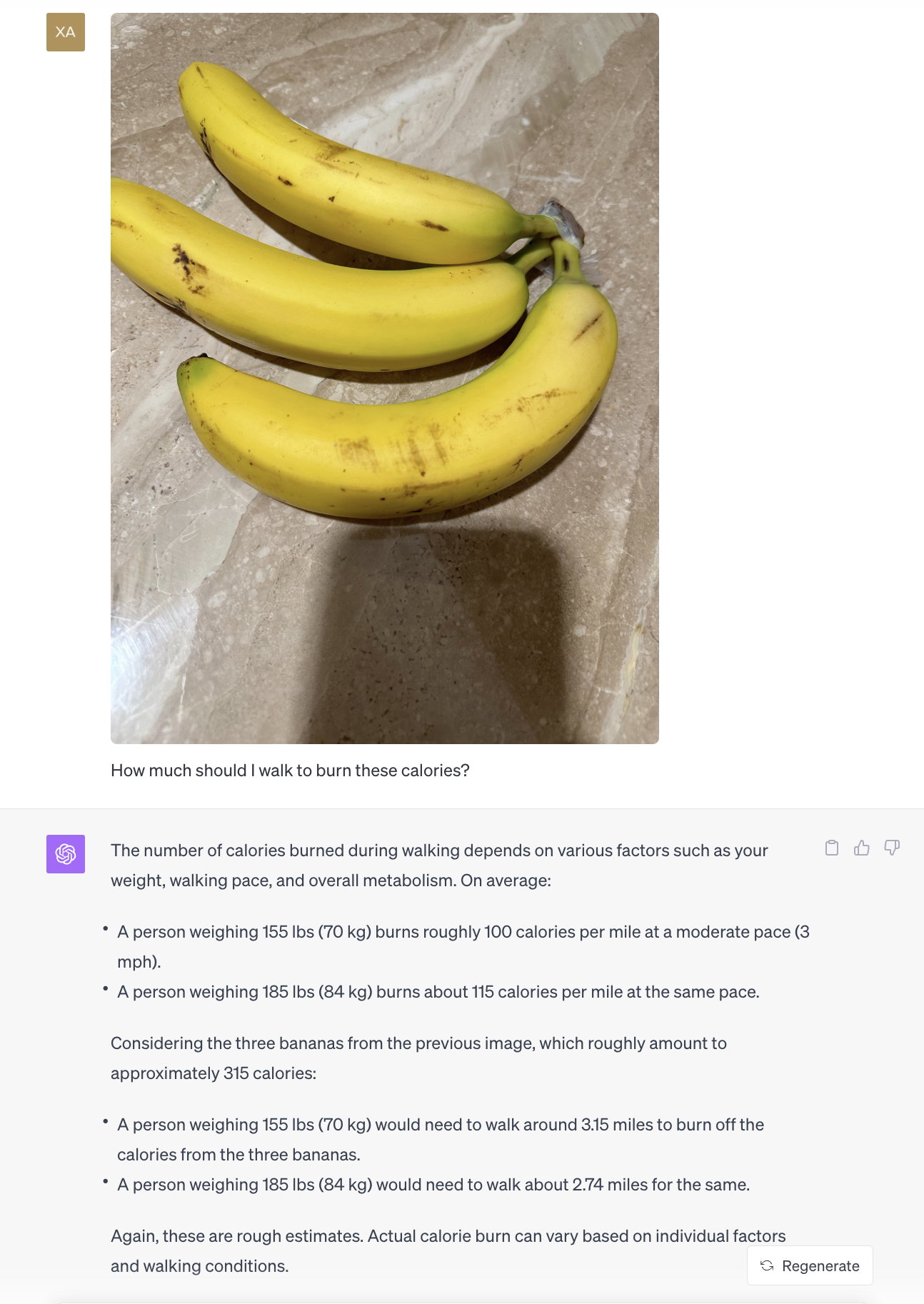
Diagram Analysis: For those delving into the intricate world of neural networks, diagrams can often seem enigmatic. Take, for instance, a Two Tower Deep Neural Network recommender system. With GPT-4’s multimodal prowess, one can upload the diagram and receive a comprehensive breakdown. The AI describes its architecture, the intricacies of its design, and even potential applications and improvements.

Multimodal Post Creation: The synergy between image generation and text generation is truly a marvel in the multimodal AI arena. As a firsthand illustration, I employed DALL-E 3 to generate an imaginative image of a multi-layered cake, where each distinct layer represents a different activity in developing a GenAI application. Not stopping there, I then fed this uniquely conceptualized cake image into GPT-4, which adeptly assisted in crafting the text for my previous post . This process not only showcases the formidable image recognition capabilities of GPT-4 but also the innovative image generation powers of DALL-E 3, offering a comprehensive peek into the holistic potential of multimodal AI.
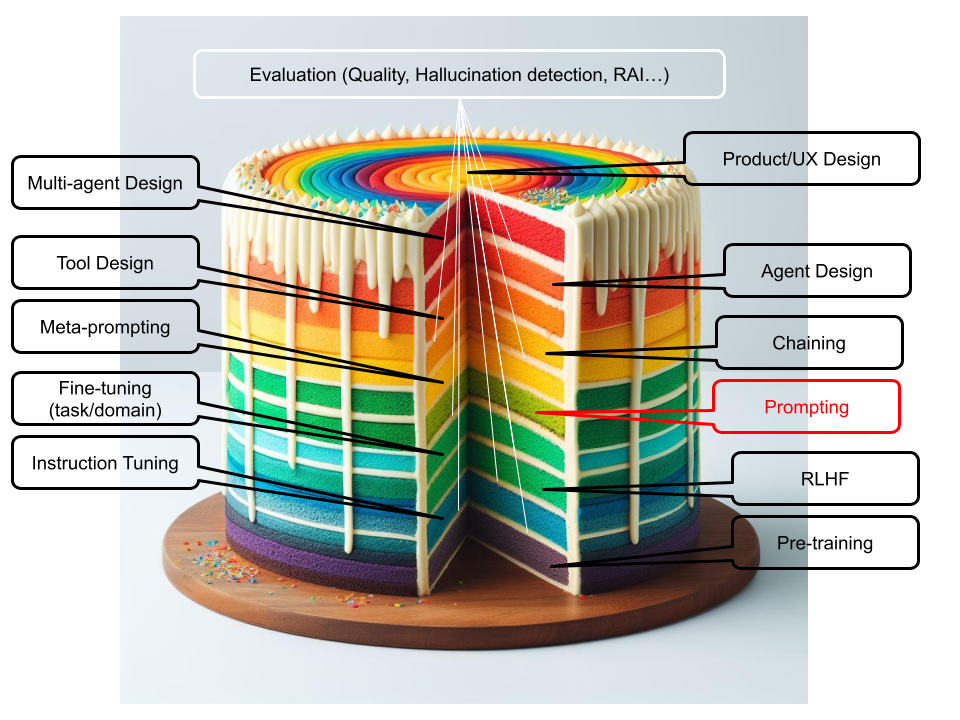
These examples are merely the tip of the iceberg. As we continue to explore and innovate, the symbiotic relationship between humans and AI will lead to unimaginable advancements. The Multimodal Generative AI Revolution is not just knocking on our doors; it’s here, ready to reshape the future. Embrace it and let’s co-create a world where technology doesn’t just complement our lives but elevates it to realms previously thought to be the domain of science fiction.



