(This blog post, as most of my recent ones, is written with GPT-4 assistance and augmentation)
Large Language Models (LLMs) like GPT-4 are often simplified as mere probabilistic token predictors, a perspective I’ve shared in the past to demystify their capabilities and temper the surrounding hype. Yet, this view undersells the true sophistication of modern LLMs. If you’ve had the opportunity to interact with frontier models such as GPT-4, you might have noticed abilities that hint at something beyond simple token prediction. This post isn’t about convincing you of their advanced capabilities—that should be evident to users of such models. Instead, we’ll delve into the technical underpinnings that elevate LLMs above mere token prediction, exploring the intricate processes involved in their development and training.
Emerging abilities, such as understanding context, generating coherent and creative text, and even exhibiting problem-solving skills, suggest that these models are tapping into deeper layers of language comprehension and generation. How do they achieve this? Is it merely an extension of their token prediction capability, or is there something more at play? By unpacking the mechanisms that drive these advanced models, I will attempt to shed light on the true extent of their capabilities and the implications for the future of artificial intelligence.
The Token Prediction Component - A bit on basic LMs and Transformers
Language models, at their core, are designed to predict the next word in a sentence based on the context provided by the preceding words. This concept, simple in theory, has evolved dramatically over time. Initially, models relied on basic statistical methods, predicting words based on their likelihood of following a given sequence. The introduction of ULMFit by Jeremy Howard in 2017 marked a significant leap forward, advocating for the pre-training of a ‘universal’ model on a vast corpus, which could then be fine-tuned for specific tasks. This approach paved the way for even more sophisticated models.
The same year, the groundbreaking ‘Attention is All You Need’ paper by Google researchers introduced the world to Transformers. These models, which have dominated the landscape of language models in recent years, employ a unique mechanism that focuses on the context of each word within a sentence, regardless of its position. This enables a more nuanced understanding and generation of text. While I’ve delved deeper into Transformers in previous writings (see blogpost and publication versions of my Transformer Catalog), it’s essential to recognize them as the backbone of modern LLMs, which, despite their complexity, still fundamentally rely on predicting the most likely next word in a sequence.”
Beyond Basic Prediction: The Advent of Instruction-Focused LLMs
As we delve deeper into the evolution of Large Language Models, a significant milestone emerges with OpenAI’s introduction of InstructGPT in 2022. This model marked a departure from traditional training methodologies by emphasizing the model’s ability to follow human instructions more effectively. InstructGPT leveraged the concept of fine-tuning, a familiar technique in the LLM toolkit, but with a novel focus: enhancing the model’s responsiveness to nuanced human prompts.
This innovation signaled a broader shift in the LLM landscape. No longer was pre-training alone sufficient; the development of a cutting-edge LLM now required a multi-layered approach. Today’s training regimen encompasses a series of intricate steps: pre-training, instruction tuning, alignment, task-specific or multitask fine-tuning for specialized capabilities, and prompt tuning for optimized interaction.
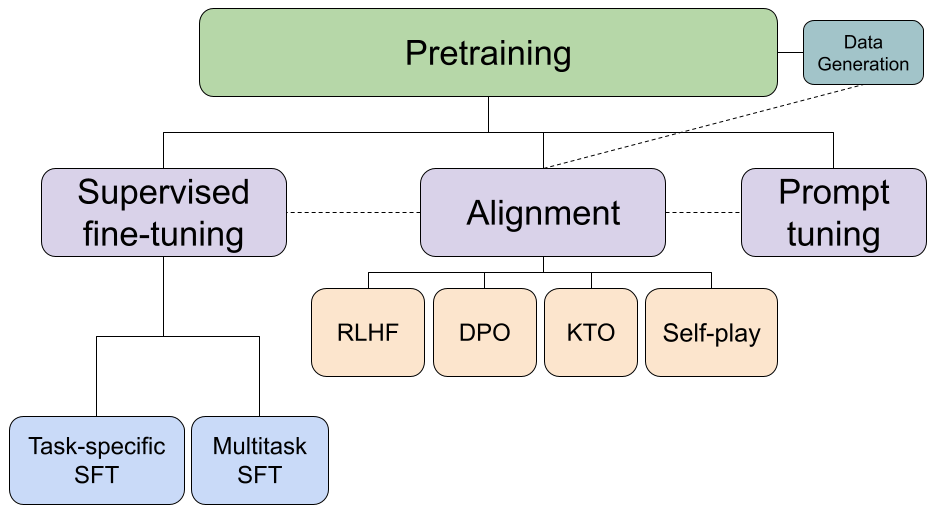 The Comprehensive Training Process for Modern LLMs: From foundational pre-training to nuanced prompt tuning, this diagram outlines the key stages in developing an LLM capable of sophisticated human interaction.
The Comprehensive Training Process for Modern LLMs: From foundational pre-training to nuanced prompt tuning, this diagram outlines the key stages in developing an LLM capable of sophisticated human interaction.
As we explore these steps further, we’ll uncover how each contributes to building LLMs that not only understand language but can also interpret and execute complex instructions with an unprecedented level of finesse. What implications do these advancements hold for the future of artificial intelligence, and how do they redefine our interaction with machines? The following sections will delve into these questions, shedding light on the intricate dance of technology and human guidance that shapes the LLMs of today.
Enhancing LLMs with Supervised Fine Tuning (SFT)
At the heart of making Large Language Models (LLMs) adept at specific tasks is Supervised Fine Tuning (SFT). This crucial step tailors a broadly trained foundation model, like BERT, to excel in distinct applications by leveraging labeled data. The seminal BERT paper exemplifies this, detailing the model’s adaptation to 11 diverse tasks, showcasing SFT’s transformative impact.
Even as recent LLMs boast impressive out-of-the-box capabilities, the targeted application of SFT can significantly amplify their performance. OpenAI’s findings underscore this, revealing that a fine-tuned GPT-3.5 Turbo can surpass GPT-4 in specialized tasks, highlighting SFT’s enduring relevance.
SFT’s versatility extends beyond single-task optimization. Multi-task fine-tuning enriches models with broader applicability, streamlining prompt engineering and potentially circumventing the need for retrieval-augmented generation. This approach not only enhances result accuracy but also introduces models to novel or exclusive datasets, ensuring their evolution in step with emerging knowledge domains.
SFT does not only improve the performance of the foundation LLM on a given or multiple tasks, but it also offers other advantages. For example, it provides a way to train the model with proprietary data that was not present in the original dataset. Or, when using Parameter Efficient Fine Tuning (PEFT) it can yield not only a more accurate, but also smaller LLM. As we will see in the next section, SFT can also be used to have the model become better at following human instructions.
Improving Human-Model Interaction through Instruction Tuning
Instruction Tuning stands as a pivotal application of fine-tuning, meticulously crafting LLMs to better comprehend and execute tasks (aka instructions) as defined by human prompts. At its core, instruction tuning refines a model’s ability to parse and respond to task-specific instructions, ensuring outcomes that resonate with human expectations.
Central to this process are specialized datasets like Natural Instructions, which offer a rich tapestry of task definitions, exemplars, and critical dos and don’ts. These datasets serve as the blueprint for instruction tuning, guiding models to grasp the nuanced spectrum of human instructions. Note: As we navigate the intricacies of aligning LLMs with human intent, it’s imperative to consider the ethical implications and ensure that instruction datasets embody a broad spectrum of perspectives, thereby fostering models that are both high-performing and equitable.
The efficacy of instruction tuning is underscored by comparative analyses of models like InstructGPT and Alpaca, which, post-tuning, exhibit marked superiority over their foundational counterparts, GPT-3 and LLaMA, respectively. These enhancements are not merely incremental; they redefine the models’ utility across a range of benchmarks, from natural language understanding to task-specific problem-solving.
Steering LLMs Towards Human Values: Alignment Approaches and Techniques
AI alignment emerges as a critical endeavor in the development of LLMs, ensuring these models act in accordance with human goals, principles, and preferences. Despite their sophistication, LLMs can inadvertently generate content that is biased, misleading, or harmful. Addressing these challenges requires a suite of alignment techniques, each with its unique approach and application. Note that instruction tuning is in itself a first step towards alignment.. And, according to some recent research, only large models beyond 7 billion parameters benefit from more complex alignment methods.
Reinforcement Learning from Human Feedback (RLHF) simplifies the complex process of aligning LLM outputs with human judgment. By employing a reward model trained on human feedback, RLHF fine-tunes LLMs to produce responses that better match human expectations. This iterative process involves evaluating LLM outputs and adjusting based on human-rated preferences, fostering a closer alignment with desired outcomes. In a recent research, Deepmind researchers show that choosing the right approach to eliciting the human feedback, for example by tweaking the exploration/exploitation aspect of the process using Thompson Sampling, can improve results significantly.
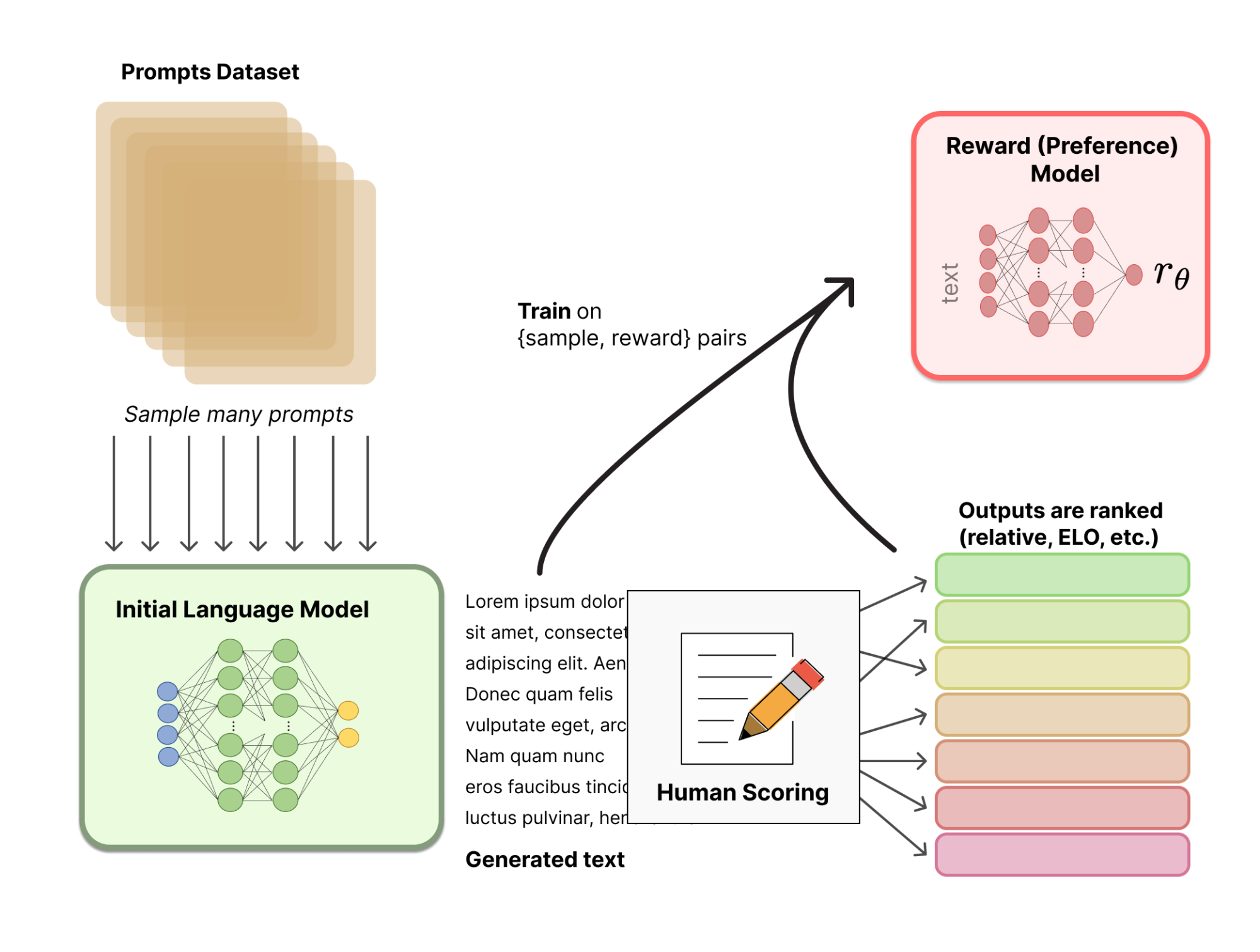
Reinforcement Learning from AI Feedback (RLAIF), in contrast, leverages existing, well-aligned models to guide the training of LLMs. This approach enables LLMs to learn from the vast, nuanced understanding embedded in these advanced models, accelerating the alignment process without direct human intervention.
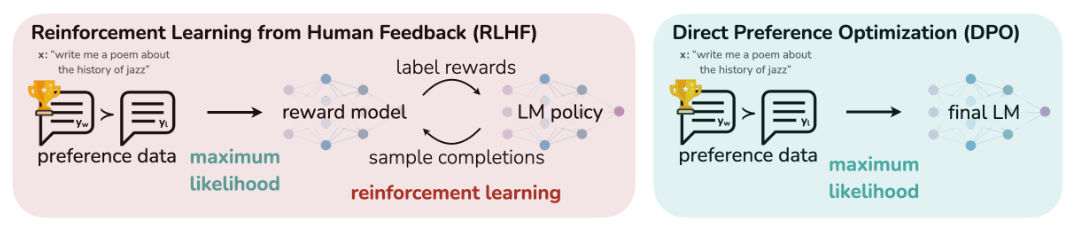
Direct Preference Optimization (DPO) addresses some of the challenges inherent in RLHF, such as its complexity and instability. DPO optimizes alignment by directly training LLMs on human preferences, bypassing the need for a separate reward model. This streamlined approach results in more stable, efficient, and effective alignment, particularly in controlling the tone and quality of LLM responses.
Kahneman-Tversky Optimization (KTO) introduces a novel paradigm by eliminating the need for paired preference data. Instead, KTO evaluates outputs based solely on their desirability, simplifying the data requirements and making alignment more accessible, especially for organizations with abundant customer interaction data.
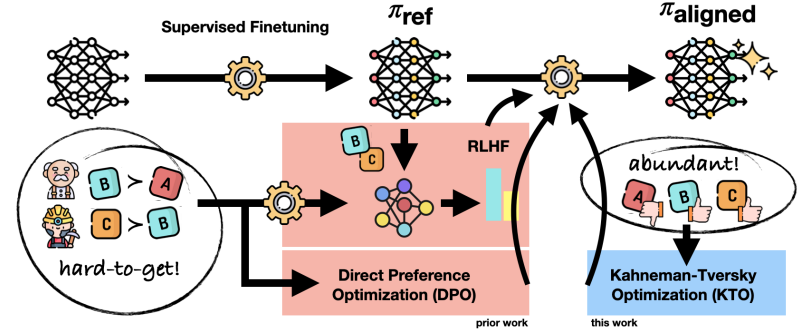
Self-Play Fine-Tuning (SPFT) adopts a unique approach by enabling LLMs to learn from their own generated content. This self-reflective method allows LLMs to refine their understanding and generation of language through a process of internal trial and error, leading to significant improvements across various benchmarks.

It should be noted that there are pre-pretraining techniques that can also help with alignment. In fact, Microsoft researchers showed in their work with Phi that using carefully crafted synthetic data in the pretraining step can lead to more alignment than using post pretraining techniques like RLHF (see more details in the Phi-2 model blog post here.
Fine-Tuning Interaction: The Art of Prompt Tuning
As LLMs approach deployment, prompt tuning becomes essential, refining the interface through which humans communicate with these models. Prompt tuning involves crafting and optimizing the prompts used to elicit specific responses or actions from the LLM in zero-shot or few-shot learning scenarios. Note that prompt tuning, just as instruction tuning, can be used to improve alignment. However, it has many other applications beyond that one.
At the heart of prompt tuning are meta-prompts and prompt templates—scaffolds that guide the model’s understanding and generation of responses. Meta-prompts are higher-level instructions that contextualize the task, while templates provide a structure for the input and expected output. For instance, a meta-prompt might instruct the LLM to provide advice, while the template structures this advice within a specific format or style.
The iterative nature of prompt tuning hinges on rigorous evaluation criteria. These benchmarks assess prompts on various dimensions, such as the relevance and coherence of the LLM’s responses, ensuring that the final prompts align closely with user intentions and task requirements.
Through practical examples, such as optimizing prompts for a customer service chatbot or a content generation tool, we can observe the transformative impact of prompt tuning. These cases underscore the heightened efficiency and specificity with which tuned LLMs can address tasks, heralding a new era of human-AI interaction.
For those eager to explore the intricate strategies and methodologies of prompt design and engineering, I invite you to delve into my recent publication, which provides a comprehensive exploration of this field.
Conclusion
In light of our exploration, it’s evident that modern Large Language Models (LLMs) transcend their foundational token-predicting capabilities. From the nuanced fine-tuning for specific tasks to the sophisticated alignment with human values and the artful crafting of prompts, each step in the development of LLMs contributes layers of complexity and adaptability, making them far more than mere token predictors.
The precise impact of each stage on the LLMs’ emerging abilities remains a fascinating puzzle, one that invites further investigation and discussion within the AI community. As we stand on the brink of new advancements, the potential for unforeseen capabilities and applications of LLMs continues to expand, challenging our understanding and expectations.
So, the next time the conversation turns to the nature of LLMs, remember that these models are the product of a rich tapestry of innovations, each adding depth and dimension to their interactions with the world. Let’s embrace the complexity and continue to push the boundaries of what these extraordinary tools can achieve