(I recently turned this guide into a paper. You can find it here)
- Introduction
- What we talk about when we talk about Hallucinations
- How to Measure
- Mitigating Hallucinations: a multifacted approach
- Conclusion: Yann vs. Ilya
Introduction
Ever been curious about the complexities of integrating large language models (LLMs) into user-facing products? One challenge that has been gaining attention is the occurrence of ‘hallucinations’—situations where these advanced AI systems produce misleading or incorrect information. This is a real-world issue that many of us in the tech industry are actively working to address as we develop new features and services.
In this blog post, you’ll find a comprehensive guide to the most effective strategies for mitigating these hallucinations in user-facing products. The field is fast-evolving, so while I don’t plan on continuously updating this post, I hope it serves as a valuable snapshot of current best practices. I’m also open to your insights and ideas, so feel free to reach out with any suggestions or questions you might have.
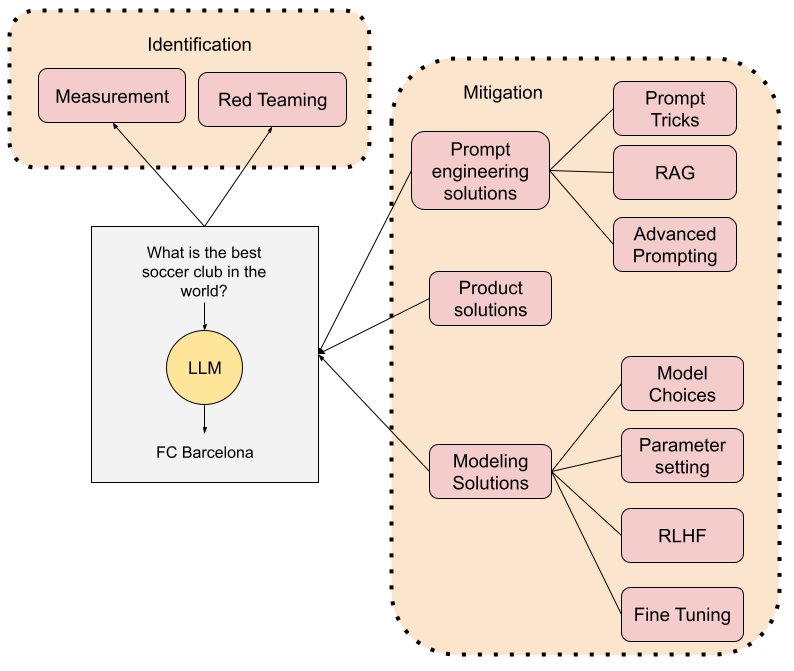
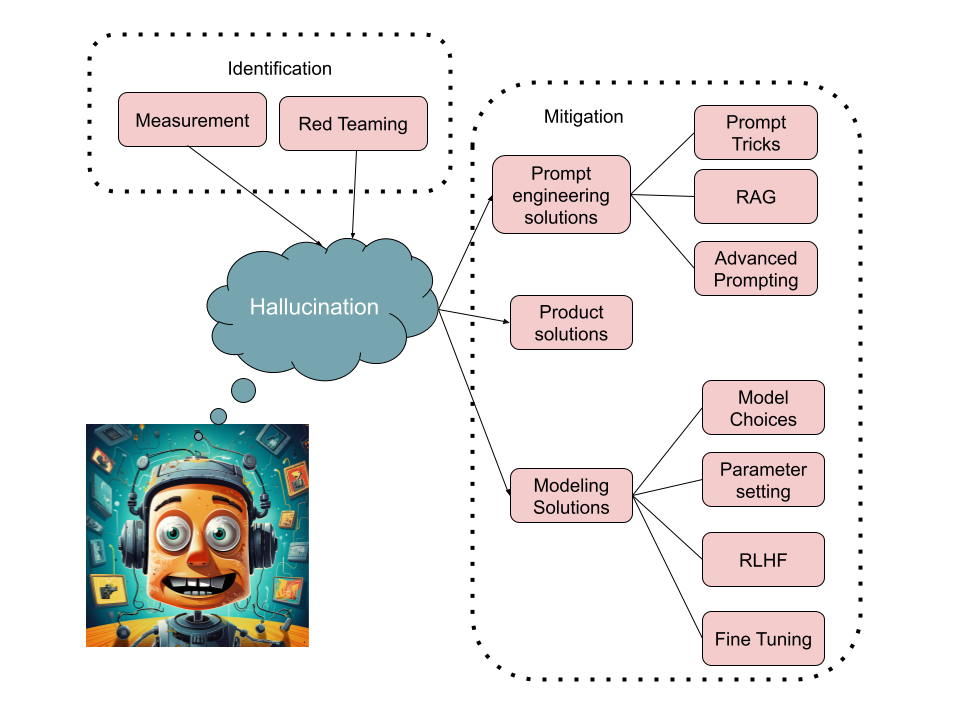 A multifaceted approach to mitigating LLM hallucinations
A multifaceted approach to mitigating LLM hallucinations
What we talk about when we talk about hallucinations
In the context of Large Language Models (LLMs), the term “hallucinations” often surfaces. As defined by the “Survey of Hallucination in Natural Language Generation” paper, a hallucination in an LLM refers to “the generation of content that is nonsensical or unfaithful to the provided source.”
A Controversial Term: Unpacking the Use of “Hallucination” in AI
According to Wikipedia, a hallucination is defined as “a perception in the absence of an external stimulus that has the qualities of a real perception.” Such a description might evoke images of mysterious visions or imagined sounds. However, the term has taken on a different, though not uncontroversial, shade of meaning in the realm of artificial intelligence.
There are three main concerns I’ve come across regarding the use of “hallucination” to describe phenomena in AI systems:
- Misattribution of Properties: The application of “hallucination” might inadvertently suggest that LLMs possess some form of consciousness or perception, which they certainly don’t. LLMs generate text based on patterns in their training data, not because they “perceive” or “imagine” in the way living creatures do.
- Misunderstanding of Dynamics: Such terminology might cloud understanding about how LLMs function. They don’t “see” or “imagine.” Instead, they churn out text based on statistical patterns from their training data.
- Ethical Implications: There’s a fear that describing AI outputs as “hallucinations” trivializes the potential risks of LLMs providing incorrect or misleading information, especially if users over-rely on these models without proper fact-checking.
However, the AI context for “hallucination” has even been acknowledged by dictionaries. For instance, Merriam-Webster defines it in the context of AI as “a plausible but false or misleading response generated by an artificial intelligence algorithm.”
Interestingly, this term isn’t freshly minted. Andrej Karpathy suggested that he might have popularized the term in his enlightening blog post from 2015. But a little digging reveals earlier uses. Notably, an ACL conference paper from 2014 discussed “hallucinating” translations. Even further back, a 2009 paper titled “Review Sentiment Scoring via a Parse-and-Paraphrase Paradigm” used the term in the context of “hallucinating” topics. But perhaps the most ancient reference I found was in a 1996 paper, “Text Databases and Information Retrieval”, which talked about systems that could “hallucinate” words not present in the original document.
In my view, it’s clear that “hallucination” in AI has been in the lexicon for some time, carving out a niche meaning, distinct from its psychological roots.
It’s also worth noting that AI is replete with terms borrowed from human analogies - take “neural networks” for instance. Despite initial reservations, these terms have become integral, largely uncontroversial components of AI discourse.
Types of Hallucinations
Hallucinations can be categorized into two main types:
- Intrinsic Hallucinations: These directly contradict the source material, introducing factual inaccuracies or logical inconsistencies.
- Extrinsic Hallucinations: These do not contradict but also cannot be verified against the source, adding elements that could be considered speculative or unconfirmable.
The Nuanced Role of the ‘Source’
The concept of a ‘source’ varies depending on the specific task an LLM is performing. In dialogue-based tasks, the source can be considered as ‘world knowledge.’ However, when the task involves text summarization, the source is the input text itself. This is a critical nuance that significantly impacts both the evaluation and interpretation of hallucinations.
Contextual Importance of Hallucinations
The implications of hallucinations are highly context-dependent. For example, in creative applications such as poem-writing, the presence of hallucinations may not only be acceptable but could potentially enrich the output.
Why do LLMs hallucinate
It is important to first keep in mind that LLMs have been pre-trained to predict tokens. They do not have a notion of true/false or correct/incorrect, but rather base their text generation on probabilities. While that leads to some unexpected reasoning abilities (such as being able to pass the legal BAR exam or the medical USMLE), that is only a result of this probabilistic token by token reasoning. To be fair, the additional training steps of instruct tuning and RLHF that most modern LLMs have do introduce a bit more “bias towards factuality”, but they do not change the overal underlying mechanism and its pitfalls.
LLMs have been trained on the whole internet, book collections, question/answers, and Wikipedia, among many others. They have good and not-so-good knowledge in their training set. Their responses are biased towards whatever they have seen the most. If you ask an LLM a medical question and you are not careful on how you prompt it, you might get an answer that is mostly aligned to the best medical literature or to random Reddit threads.
In a recent paper entitled “Sources of Hallucination by Large Language Models on Inference Tasks”, the authors show how hallucinations are originated by two aspects of the LLM’s training dataset: veracity prior and the relative frequency heuristic.
How to Measure Hallucinations in Large Language Models
Understanding hallucinations is one thing, but quantifying them? That’s where things get really interesting. Quantitative metrics are essential for assessing the effectiveness of mitigation strategies. In this section, I’ll guide you through the recommended methodologies for measuring hallucinations.
A Five-Step Approach to Quantitative Measurement
Based on best practices in the field, here’s a systematic five-step approach to accurately measure hallucinations:
1. Identify Grounding Data: Grounding data serves as the benchmark for what the LLM should produce. The choice of grounding data varies by use-case. For instance, actual resumes could serve as grounding data when generating resume-related information. On the other hand, search engine results could be used for web-based queries.
2. Create Measurement Test Sets: These sets usually consist of input/output pairs and may include human-LLM conversations, depending on the application. Ideally, you’d have at least two types of test sets: * A generic or random test set * An adversarial test set, generated from red-teaming exercises to include challenging or high-risk edge cases.
3. Extract Claims: After preparing the test sets, the next step is to extract claims made by the LLM. This can be done manually, through rule-based methods, or even using machine learning models. Each technique has its pros and cons, which we will explore in detail.
4. Validate Against Grounding Data: Validation ensures that the LLM’s generated content aligns with the grounding data. This step often mirrors the extraction methods used previously.
5. Report Metrics: The “Grounding Defect Rate” is a fundamental metric that quantifies the ratio of ungrounded responses to the total number of generated outputs. Additional metrics will be discussed later for a more nuanced evaluation.
Evaluating Hallucinations: Common Metrics and Methodologies
Quantifying hallucinations in Large Language Models isn’t just about recognizing that they exist—it’s about measuring them rigorously. In this section, I’ll delve into the different types of metrics commonly employed for this purpose.
Statistical Metrics
Metrics like ROUGE and BLEU are often the go-to choices for text similarity evaluations. They focus on the intrinsic type of hallucinations by comparing the generated output against a source. Advanced metrics such as PARENT, PARENT-T, and Knowledge F1 come into play when a structured knowledge source is available. However, these metrics have limitations: they primarily focus on intrinsic hallucinations and can falter when capturing syntactic and semantic nuances.
Model-Based Metrics
Model-based metrics leverage neural networks, making them more adaptable to syntactic and semantic complexities. They come in various flavors:
IE-based Metrics: These use Information Extraction (IE) models to distill the knowledge into a simpler relational tuple format—think subject, relation, object. The model then validates these tuples against those extracted from the source or reference.
- QA-based Metrics: These implicitly measure the overlap or consistency between the generated content and the source. If the content is factually consistent with the source, similar answers will be generated to the same questions. (see e.g. “Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering”)
- NLI-based Metrics: Utilizing Natural Language Inference (NLI) datasets, these metrics determine if a generated “hypothesis” is true, false, or undetermined given a “premise”.(see e.g. “Evaluating Groundedness in Dialogue Systems: The BEGIN Benchmark”).
- Faithfulness Classification Metrics: These improve upon NLI-based metrics by creating task-specific datasets, thereby providing a more nuanced evaluation. . (see e.g. “Rome was built in 1776: A Case Study on Factual Correctness in Knowledge-Grounded Response Generation”).
The Role of Human Evaluation
Despite the sophistication of automated metrics, human evaluation still holds significant value. Two primary approaches are commonly employed:
- Scoring: Human annotators assign scores within a defined range to rate the level of hallucination.
- Comparing: Here, human annotators evaluate the generated content against baselines or ground-truth references, providing an additional layer of validation.
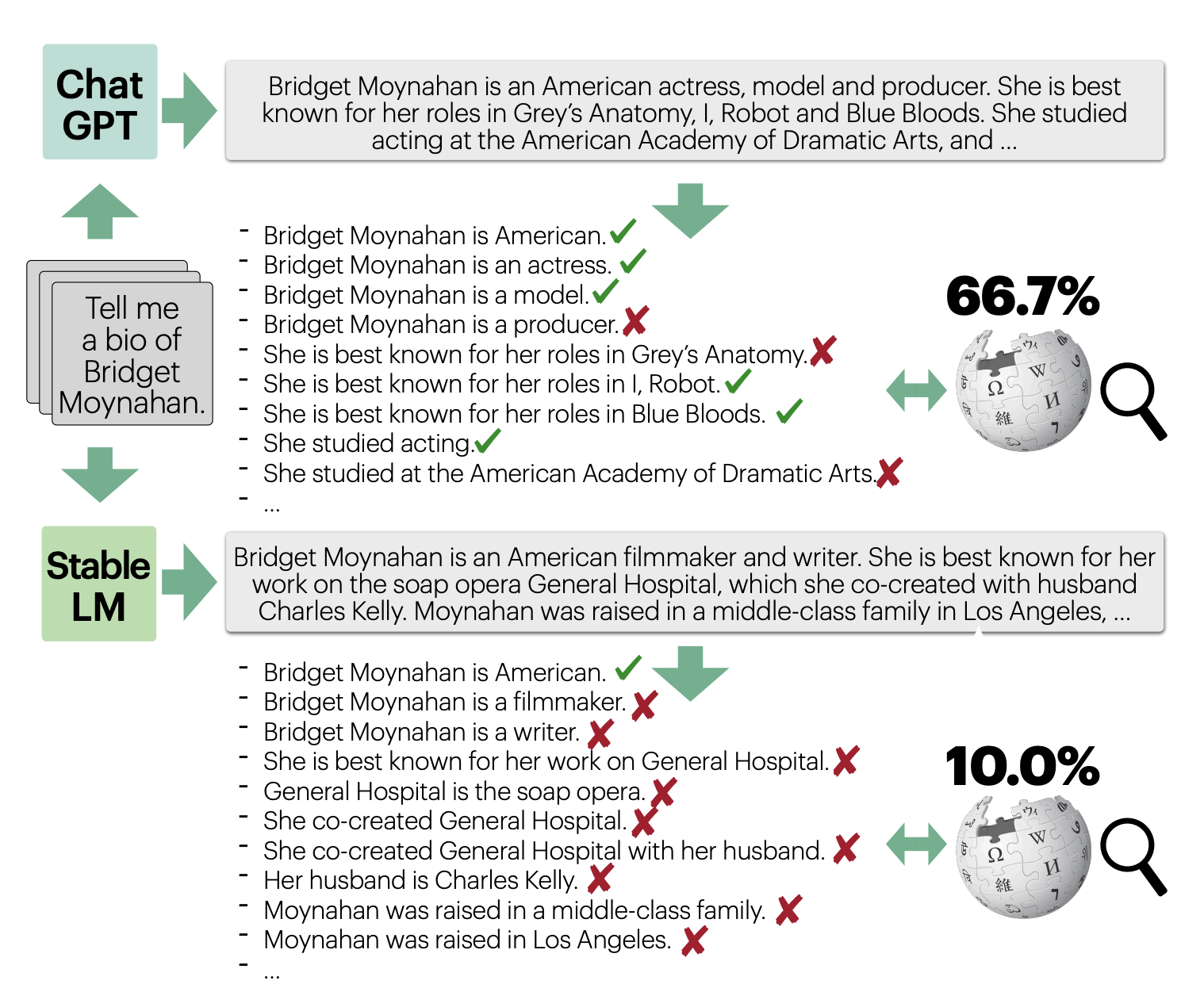
The example of FActScore
FActScore is a recent example of a metric that can be used both for human and model-based evaluation. The metric breaks an LLM generation into “atomic facts”. The final score is computed as the sum of the accuracy of each atomic fact, giving each of them equal weight. Accuracy is a binary number that simply states whether the atomic fact is supported by the source. The authors implement different automation strategies that use LLMs to estimate this metric.
The Art of Red Teaming: Best Practices for Stress-Testing LLMs
While statistical and model-based metrics are indispensable for measuring hallucinations in LLMs, it’s equally important to put these models through the rigor of human evaluation. Red teaming provides an essential layer of scrutiny that complements systematic measurement. Here are some best practices to follow:
Keep Red Teaming Complementary: Although red teaming and stress-testing are invaluable tools, they should not replace systematic measurement. They are meant to augment, not substitute.
Test in Real-world Conditions: Whenever possible, conduct your testing on the production endpoint. This allows for a more realistic assessment of how the model behaves under actual conditions.
Define Harms and Guidelines: Clearly outline the potential harms and provide specific guidelines to the testers. This ensures that everyone is aligned on what to look for during testing.
Prioritize Your Focus Areas: Identify the key features, harms, and scenarios that should be prioritized in the red teaming exercise. This focused approach yields more actionable insights.
Diverse and Skilled Testers: A diverse set of testers with different areas of expertise can provide a multi-faceted evaluation. Diversity here can mean different domains of knowledge, different cultural backgrounds, or even different biases.
Documentation is Key: Decide in advance what kinds of data or findings you’d like your testers to document. Clear documentation aids in a more structured evaluation process.
Manage Tester Time and Well-being: Determine how much time each tester should ideally dedicate to the task. Moreover, be cognizant of potential burnout or a decline in creativity over time, and plan accordingly.
New approaches to red teaming include using an LLM to read team another LLM. See e.g. Deepmind’s “Red Teaming Language Models with Language Models”
Mitigating Hallucinations in Large Language Models: A Multifaceted Approach
The road to minimizing hallucinations is paved with both challenges and opportunities. In this section, we’ll explore various mitigation strategies that can be customized to fit the unique demands of different applications of large language models.
Leverage Product Design to Minimize Impact
The first piece of advice is straightforward: if possible, design your use case in such a way that hallucinations become a non-issue. For instance, in applications that generate written content, focusing on opinion pieces rather than factual articles may naturally lower the risk of problematic hallucinations.
Product-Level Recommendations
- User Editability: Allow users to edit AI-generated outputs. This not only adds an extra layer of scrutiny but also improves the overall reliability of the content.
- User Responsibility: Make it clear that users are ultimately responsible for the content that is generated and published.
- Citations and References: Enabling a feature that incorporates citations can serve as a safety net, helping users verify the information before disseminating it.
- User Optionality: Offer various operational modes, such as a “precision” mode that uses a more accurate (but computationally expensive) model.
- User Feedback: Implement a feedback mechanism where users can flag generated content as inaccurate, harmful, or incomplete. This data can be invaluable for refining the model in future iterations.
- Limit Output and Turns: Be mindful of the length and complexity of generated responses, as longer and more complex outputs have a higher chance of producing hallucinations.
- Structured Input/Output: Consider using structured fields instead of free-form text to lower the risk of hallucinations. For example, if the application involves resume generation, predefined fields for educational background, work experience, and skills could be beneficial.
Data Practices for Continuous Improvement
- Maintain a Tracking Set: A dynamic database should be maintained to log different types of hallucinations along with the necessary information to reproduce them. This can serve as a powerful tool for regression testing.
- Privacy and Trust: Given that the tracking set may contain sensitive data, adhere to best practices for data privacy and security.
Prompt Engineering: Mastering the Art of Metaprompt Design
Although large language models (LLMs) have come a long way, they are not yet perfect—especially when it comes to grounding their responses. That’s why understanding and effectively utilizing metaprompts can make a world of difference. A study revealed that simply instructing the LLM on what not to do could lower hallucination rates dramatically. Even better, guiding the model towards alternative actions slashed these rates further.
General Guidelines to Curb Hallucinations
- Simplify Complex Tasks: Break down intricate actions into simpler steps.
- Harness Affordances: Utilize built-in functions within your metaprompt.
- Use Few-Shot Learning: Include examples when you can.
- Iterative Refinement: Don’t hesitate to tweak the model’s output.
One important thing to note is that while these techniques improve grounding, they also come at a computational cost. Anyone leveraging LLMs in product design will need to balance this trade-off carefully.
Fine-Tuning Your Metaprompts
- Assertive Tone: Using ALL CAPS and highlighting certain directives can improve model compliance.
- Context is King: Providing more background information can better ground the model.
- Refinement Steps: Reevaluate the initial output and make necessary adjustments.
- Inline Citations: Ask the model to substantiate its claims.
- Framing: Approaching tasks as summarization often yields more grounded results compared to question-answering.
- Selective Grounding: Ascertain scenarios where grounding is a must versus where it may be optional.
- Reiterate Key Points: Repeating essential instructions at the end of the prompt can underline their importance.
- Echoing Input: Request the model to recap vital input details, ensuring alignment with the source data.
- Algorithmic Filtering: Utilize algorithms to sift through and prioritize the most relevant information.
In upcoming sections, we’ll dissect advanced metaprompting techniques, such as the “chain of thought” approach, and delve into how Retrieval-Augmented Generation (RAG) can be leveraged for better grounding.
Chain of Thought
Chain of thought was initially described in the “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” paper by Google researchers. The simple idea here is that given that LLMs have been trained to predict tokens and not explicitly reason, you can get them closer to reasoning if you specify those required reasoning steps. Here is a simple example from the original paper:
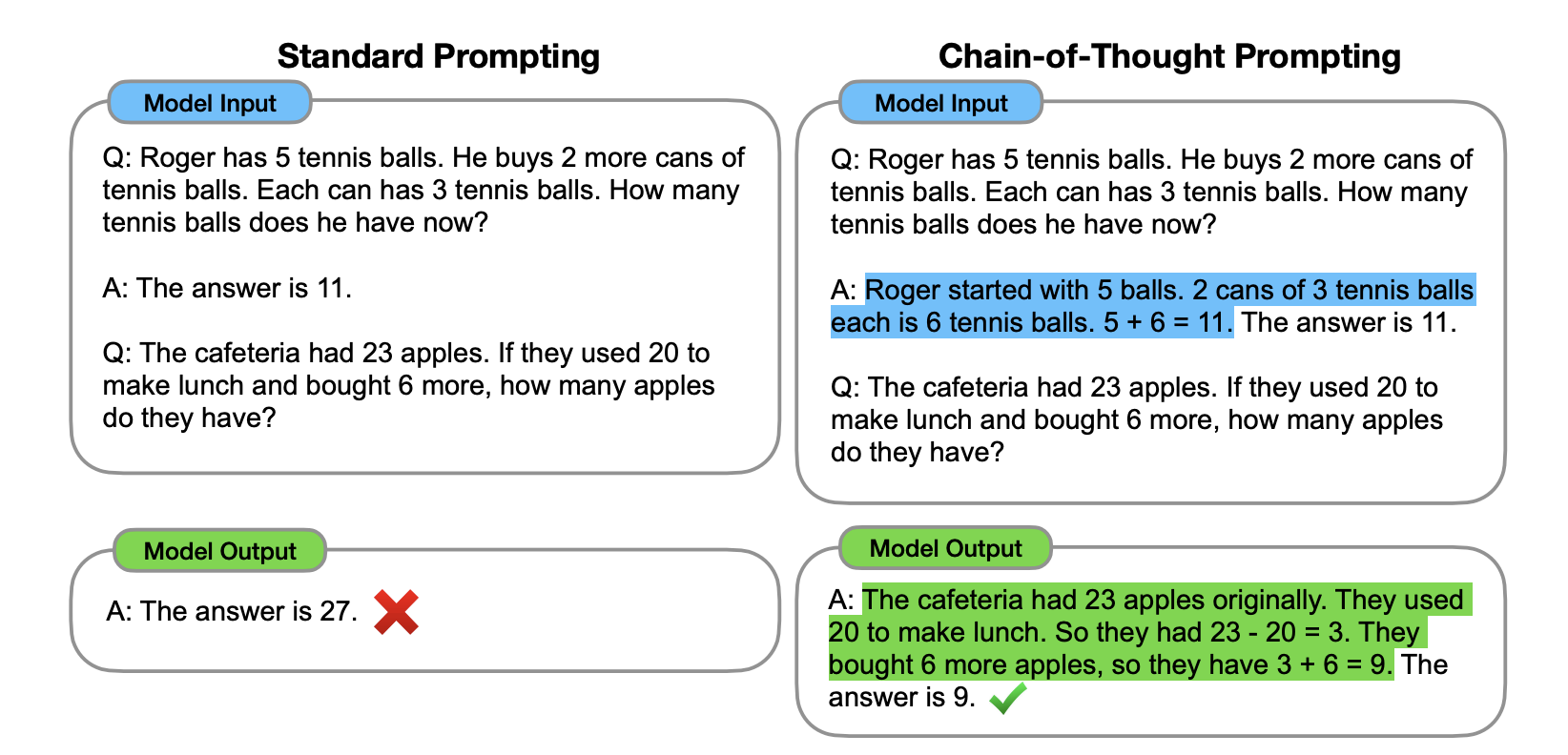
Note that in this case the “required reasoning steps” are given in the example in blue. This is the so-called “Manual CoT”. There are in fact two ways of doing basic chain of thought prompting (see below). In the basic one, called zero-shot CoT, you simply ask the LLM to “think step by step”. In the more complex version, called “manual CoT” you have to give the LLM examples of thinking step by step to illustrate how to reason. Manual prompting is more effective, but harder to scale and maintain.

CoT is just a more structured approach to the “simplify complex tasks” generic recommendation above and is known to mitigate hallucinations in many situations.
Grounding with RAG
Retrieval-Augmented Generation, commonly known as RAG, is a technique aimed at augmenting the capabilities of Large Language Models (LLMs). Initially presented by Facebook in 2020 in the context of their BART model, RAG has since been incorporated as a feature in the Hugging Face library.
The Core Concept
The fundamental idea behind RAG is straightforward: it merges a retrieval component with a generative component, allowing the two to complement each other. This process is visually explained in the diagram below, extracted from the original research paper.
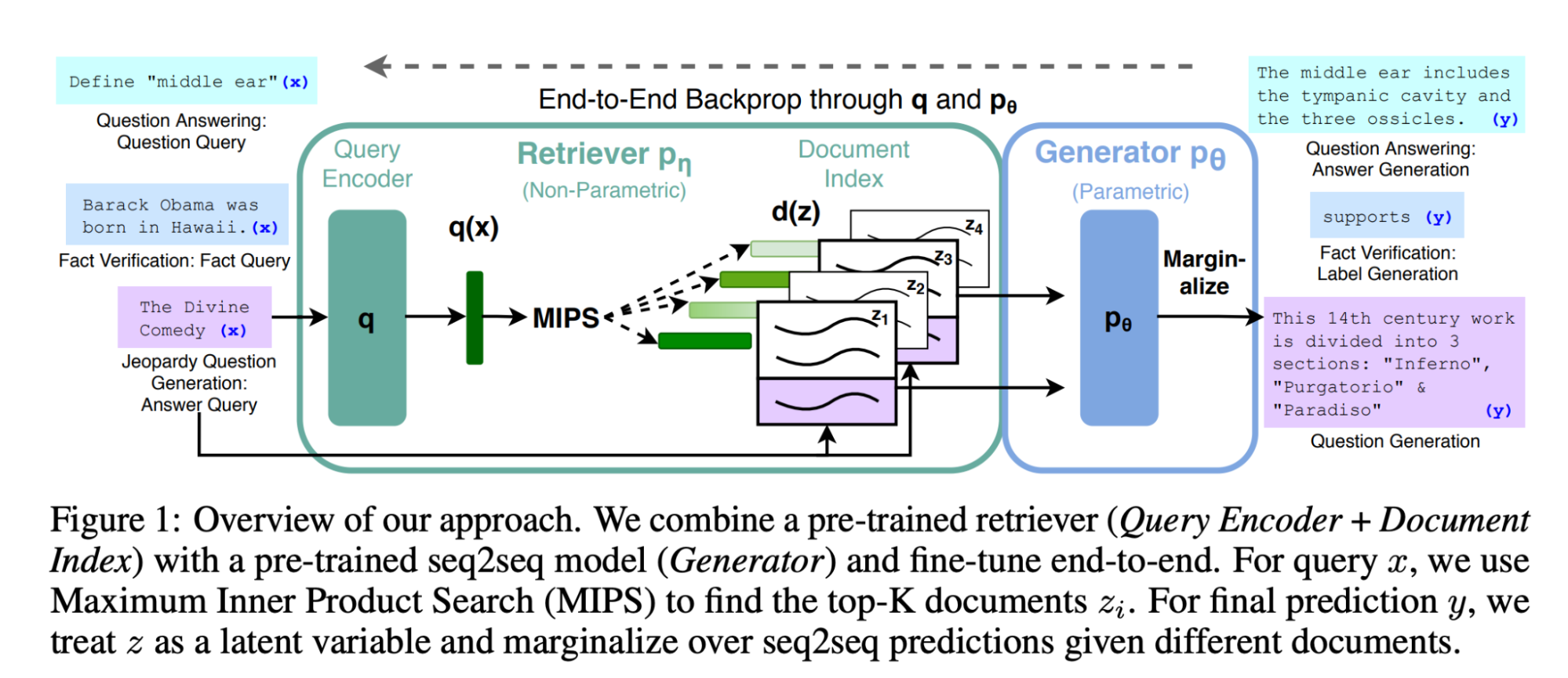
By combining these two elements, RAG enables the LLM to access and incorporate external information, thereby grounding the generated content more effectively. The retrieval component fetches relevant data, while the generative aspect of the model synthesizes this data into coherent and contextually appropriate responses.
RAG has evolved to become an indispensable part of the prompt engineer’s toolkit. Over time, it has expanded into more complex applications, effectively serving as a concrete example within the broader framework of Toolkits, where the “tool” is typically a straightforward retriever or query engine.
Because RAG grounds the response to the LLM to external data, it is known to be a very effective technique to mitigate hallucinations. However, there are some caveats.
RAG known caveats and guardrails
The Pitfall of Over-Reliance. One significant drawback of using RAG is a pronounced over-reliance on the retrieval results, which can, in certain cases, lead to hallucinations. It’s crucial to understand that retrieval might produce results that are either empty, incorrect, or require further disambiguation. Below are strategies to handle each of these scenarios.
Empty Results: Be Prepared for Voids. When the retrieval engine returns empty results, it could either be due to a lack of relevant data in the document source or an incorrect query formulation. Meta-prompts should be designed to anticipate and guard against this scenario. If the retrieval engine returns no results, the system should opt for caution and decline to answer, stating something along the lines of, “Sorry, we don’t have enough information on this topic. Could you please rephrase your question?” More advanced strategies might involve internally reformulating the query to handle issues like user misspellings, which can lead to void results.
Ambiguous Results: Seek Clarification. For ambiguous queries such as “What is a good restaurant in Portland?”, where Portland could refer to multiple locations, it’s advisable to seek further clarification from the user. For example, “Did you mean Portland, OR, or Portland, ME?”
Wrong Results: Navigate Carefully. Incorrect retrieval results are particularly challenging to address because they are difficult to identify without an external ground truth. While improving the accuracy of retrieval engines is a complex problem that’s beyond the scope of this document, we recommend analyzing the performance of your retrieval solution within your application’s specific use cases. Design your prompts to be extra cautious in areas where the retrieval engine has been identified to be less accurate.
Advanced Prompt Engineering methods
Over the past few months, significant efforts have been directed towards mitigating the issues of hallucinations and grounding in Large Language Models (LLMs). These endeavors have led to a variety of innovative approaches that tackle the problem from a prompt engineering perspective. It’s important to note that these advanced methods are distinctly different from the more straightforward “design tricks” discussed earlier. I will give a few examples of advanced prompt engineering methods that are relevant in the context of preventing hallucination. If you are interested in a more comprehensive catalog, check my previous post “Prompt Engineering 201: Advanced methods and toolkits”
Complexity, Latency, and Cost: Advanced prompt engineering techniques often introduce additional complexity, latency, and cost, primarily because they frequently involve making multiple calls to the LLM. However, it’s crucial to grasp their functionality and to have these advanced methods in your prompt engineering toolbox.
Trade-offs and Opportunities: In some cases, the incremental costs and latency might be justifiable, given the improvement in grounding and reduction in hallucinations. Additionally, you may find opportunities to implement some of these advanced methods using smaller, more cost-effective models. This could offer a valuable compromise between performance and expense.
By understanding these advanced prompt engineering methods, you can make more informed decisions about when and how to apply them, and whether their benefits outweigh their costs for your specific application.
Self-consistency
Self consistency, introduced in the paper “SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models”, is a method to use an LLM to fact-check itself. The idea is a simple ensemble-based approach where the LLM is asked to generate several responses to the same prompt. The consistency between those responses indicates how accurate the response may be.
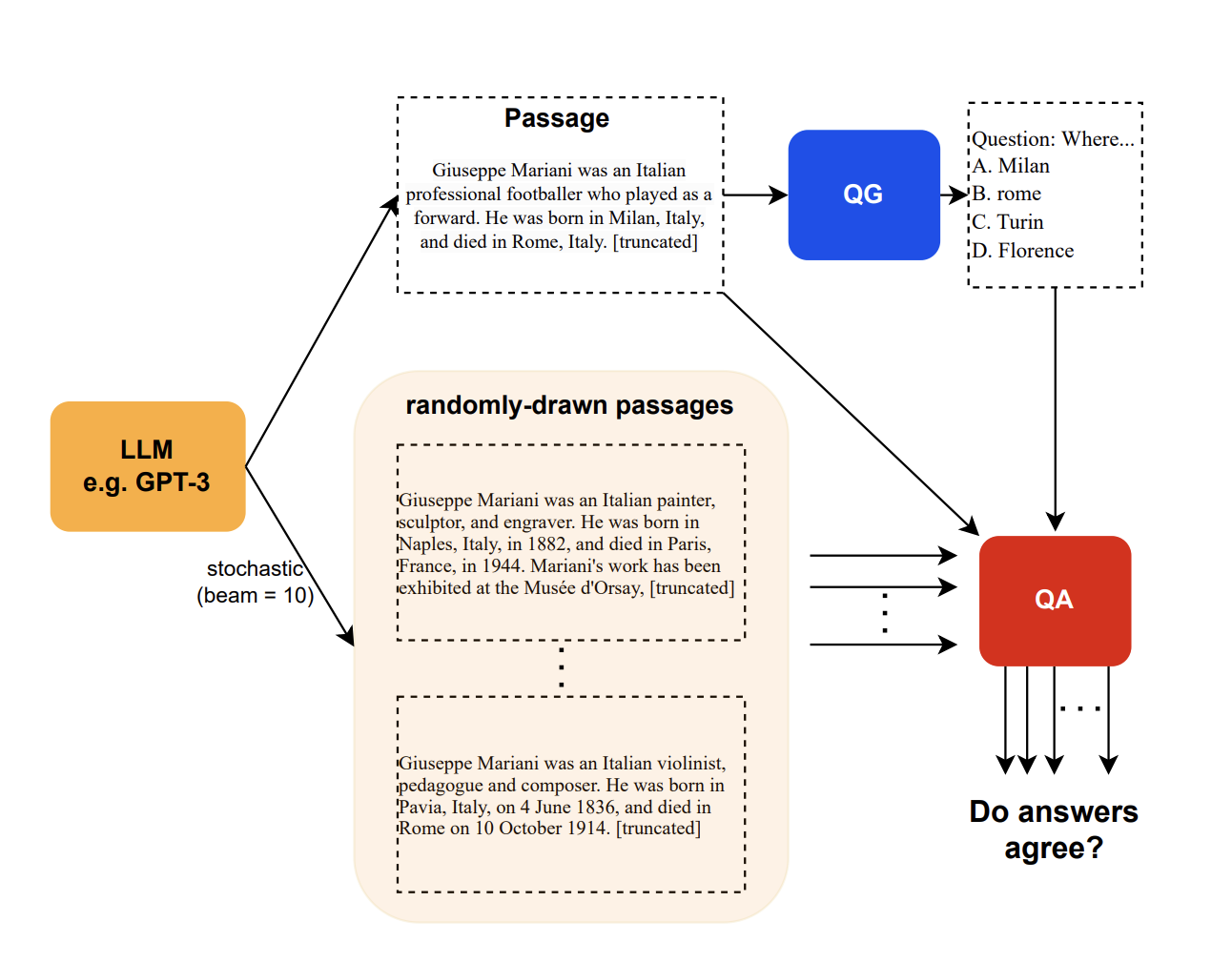
The diagram above illustrates the approach in a QA scenario. In this case, the “consistency” is measured by the number of answers to passages that agree with the overall answer. However, the authors introduce two other measures of consistency (BERT-scores, and n-gram), and a fourth one that combines the three.
Reason and act (React)
React is a specific approach to designing agents introduced by Google in “ReAct: Synergizing Reasoning and Acting in Language Models”. This method prompts the LLM to generate both verbal reasoning traces and actions in an interleaved manner, which allows the model to perform dynamic reasoning. Importantly, the authors find that the React approach reduces hallucination from CoT. However, this increase in groundedness and trustworthiness, also comes at the cost of slightly reduced flexibility in reasoning steps (see the paper for more details).

Reflection
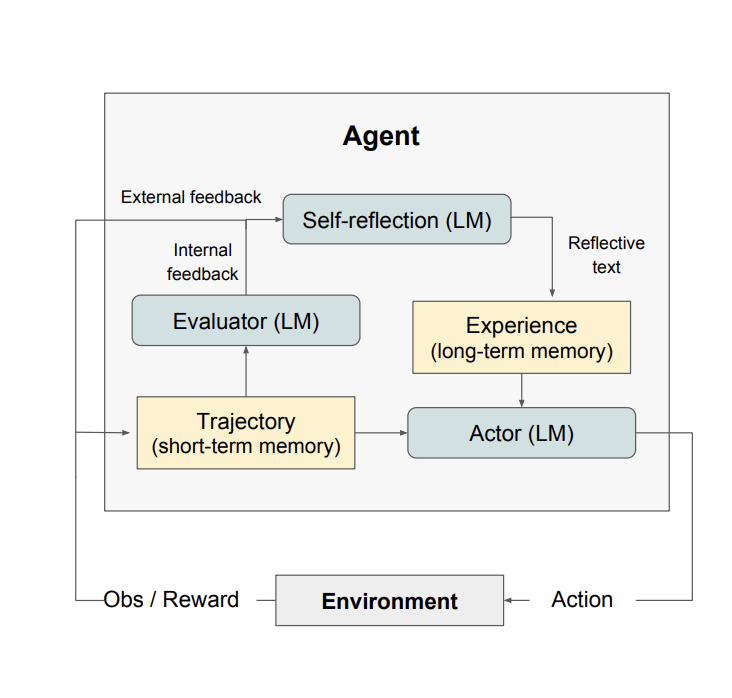
In the Self-consistency approach we saw how LLMs can be used to infer the confidence in a response. In that approach, confidence is measured as a by-product of how similar several responses to the same question are. Reflection goes a step further and tries to answer the question of whether (or how) we can ask an LLM directly about the confidence in its response. As Eric Jang puts it, there is “some preliminary evidence that GPT-4 possesses some ability to edit own prior generations based on reasoning whether their output makes sense”.
The Reflexion paper proposes an approach defined as “reinforcement via verbal reflection” with different components. The actor, an LLM itself, produces a trajectory (hypothesis). The evaluator produces a score on how good that hypothesis is. The self reflection component produces a summary that is stored in memory. The process is repeated iteratively until the Evaluator decides it has a “good enough” answer. The authors show through experiments how reflection greatly improves the ability of detecting hallucinations even when compared to a ReAct agent.
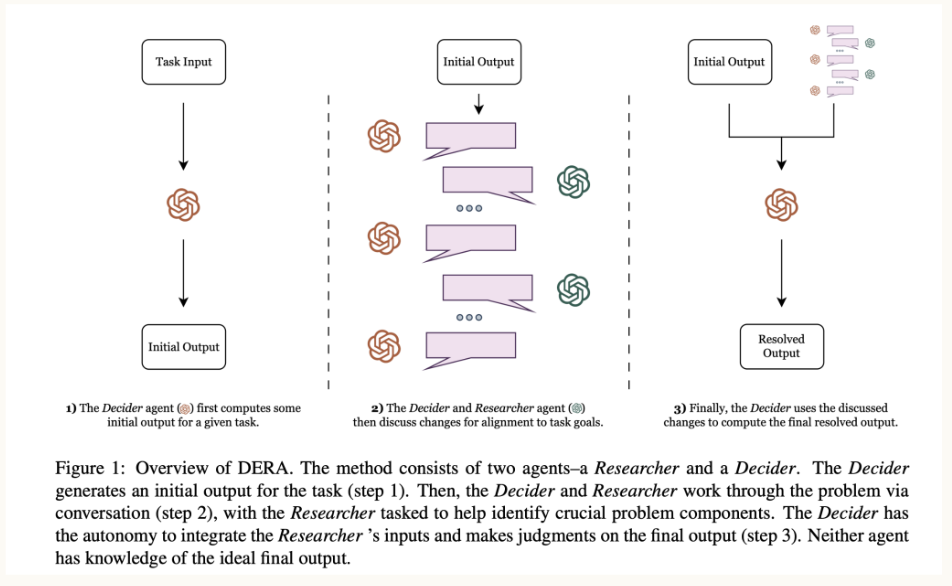
Dialog-Enabled Resolving Agents (DERA)
DERA, developed by my former team at Curai Health for their specific healthcare approach, defines different agents that, in the context of a dialog, take different roles. In the case of high stakes situations like a medical conversation, it pays off to define a set of “Researchers” and a “Decider”. The main difference here is that the Researchers operate in parallel vs. the Reflexion Actors that operate sequentially only if the Evaluator decides.
Chain-of-Verification (COVE)
COVE, recently presented by Meta, presents yet another variation on using different instances of the LLM to produce several responses and self-validate. In their approach, illustrated in the figure below, the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response.

Rails
A rail is simply a programmable way to control the output of an LLM. Rails are specified using Colang, a simple modeling language, and Canonical Forms, templates to standardize natural language sentences (see here)
Using rails, one can implement ways to have the LLM behave in a particular way. Of particular interest to our discussion, there is a rail to minimize hallucination (Fact checking rail).
Guidance (Constrained Prompting)
“Constrained Prompting” is a term recently introduced by Andrej Karpathy to describe approaches and languages that allow us to interleave generation, prompting, and logical control in an LLM flow.
Guidance is the only example of such an approach that I know although one could argue that React is also a constrained prompting approach. The tool is not so much a prompting approach but rather a “prompting language”. Using guidance templates, you can pretty much implement most if not all the approaches in this post. Guidance uses a syntax based on Handlebars that allows to interleave prompting and generation, as well as manage logical control flow and variables. Because Guidance programs are declared in the exact linear order that they will be executed, the LLM can, at any point, be used to generate text or make logical decisions.
Model Choices for Mitigating Hallucinations
Size and Model Complexity as a General Heuristic
A well-accepted guideline within the field suggests that larger, more complex models typically offer superior grounding capabilities. For example, empirical evaluations have shown that GPT-4 substantially outperforms its predecessor, GPT-3.5, in reducing the occurrence of hallucinations.
The Significance of Model Temperature
Model temperature serves as a critical hyperparameter that influences the stochastic behavior of the model’s output. In a nutshell, it determines the level of randomness when predicting subsequent tokens. Higher temperatures increase the selection probabilities for tokens that are less likely, making the model’s output more diverse but potentially less grounded. Conversely, a lower temperature, approaching zero, results in the model sticking more closely to high-probability tokens, generally yielding more reliable and grounded outputs.
Leveraging Reinforcement Learning from Human Feedback (RLHF)
RLHF methods can be applied during the later stages of training to optimize for more accurate and grounded outputs. These methods have shown marked improvements in hallucination mitigation, especially for models that have undergone domain-specific fine-tuning.
Domain adaptation through Fine-Tuning
Lastly, if you’re developing for a specific application, you might want to consider fine-tuning your internal models. Fine-tuning to your own data and examples can make a world of difference in grounding your outputs and minimizing those pesky hallucinations, particularly if you want to use a smaller and more efficient LLM. As of this writing, OpenAI offers fine-tuning for GPT-3.5 Turbo and acknowledges that in some applications this can yield better results than using the much larger and expensive GPT-4.
Conclusion
As we have seen in this discussion of hallucinations, the problem is not an easy one to solve. In fact, Yann Lecun argues that it cannot be solved without a complete redesign of the underlying models (although Ilya Sutskever disagrees). I stand somewhere in between: with the current underlying technology, hallucinations are just an expected side-effect and are hard to completely rule out. However, a combination of techniques can mitigate them and make them completely acceptable for most if not all use cases. After all, as I explained in a previous blog post, even medical doctors hallucinate!