A few weeks back I shared my thoughts on how things were going to evolve in the race to build better/larger/smarter generative AI models, and particularly LLMs. Here is what I had to say:
If you are working with LLMs, here are three important things you might want to keep in mind to anticipate how things are going to evolve in the next 6 months:*
- The best LLMs are going to be much better in all the different dimensions you probably care about (including e.g. less hallucinations)
- The best open-sourced LLMs are going to be better than the best non-open source LLMs nowadays. As an example, Facebook AI made a big announcement for their LLaMA open source model a couple of weeks back . A few days later Google announced their Flan-UL2 20B model. The latter is much better. Not as good as GPT-3.5 yet, but getting close.
- While the best LLMs in (1) are going to continue to grow in size, there are going to be models that are much smaller than the current best models yet have better capabilities. Some of them might be open sourced in (2).*
In just three weeks, a few other things that have happened have reinforced my belief, but they have also introduced a very interesting angle that I think is worth highlighting and really paying attention to. In this post I summarize these recent “trends” and discuss how to interpret them.
More and better open source foundation modelsPermalink
In just a few weeks we have seen a pretty large influx of open source foundation models. These models not only include the usual players, but other less likely subjects. After Facebook introduced LLaMA, Google presented ul2. But then we saw Databricks open source Dolly and Cerebras presented Cerebras-GPT.
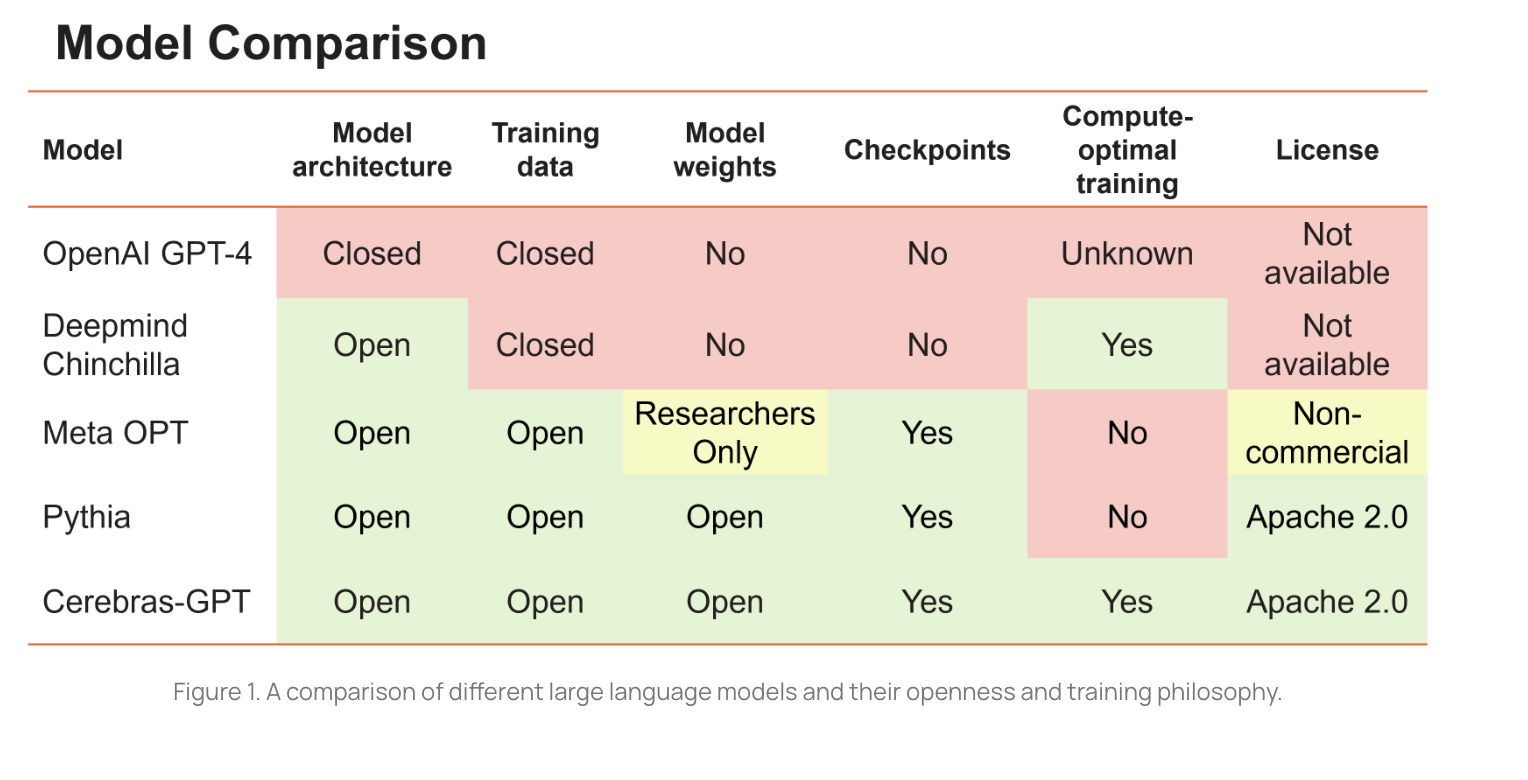
It is clear that the race for better, smaller, and more efficient models is on. It will be hard to compete with the GPT-4s of the world, but, as I mentioned above, this is not a winner-takes-all kind of market.
Improved fine-tuning and training techniquesPermalink
If you are reading this, you are probably very familiar with the idea of RLHF (Reinforcement Learning with Human Feedback). You have a longer description in my Transformer Catalog, but in summary, it is the training process in which a foundation base model is trained with labeled data from humans where annotators label pairs of prompt/responses as good or bad. It has been documented that only a few of those labels can go a long way in improving results, and, in particular, alignment in LLMs.
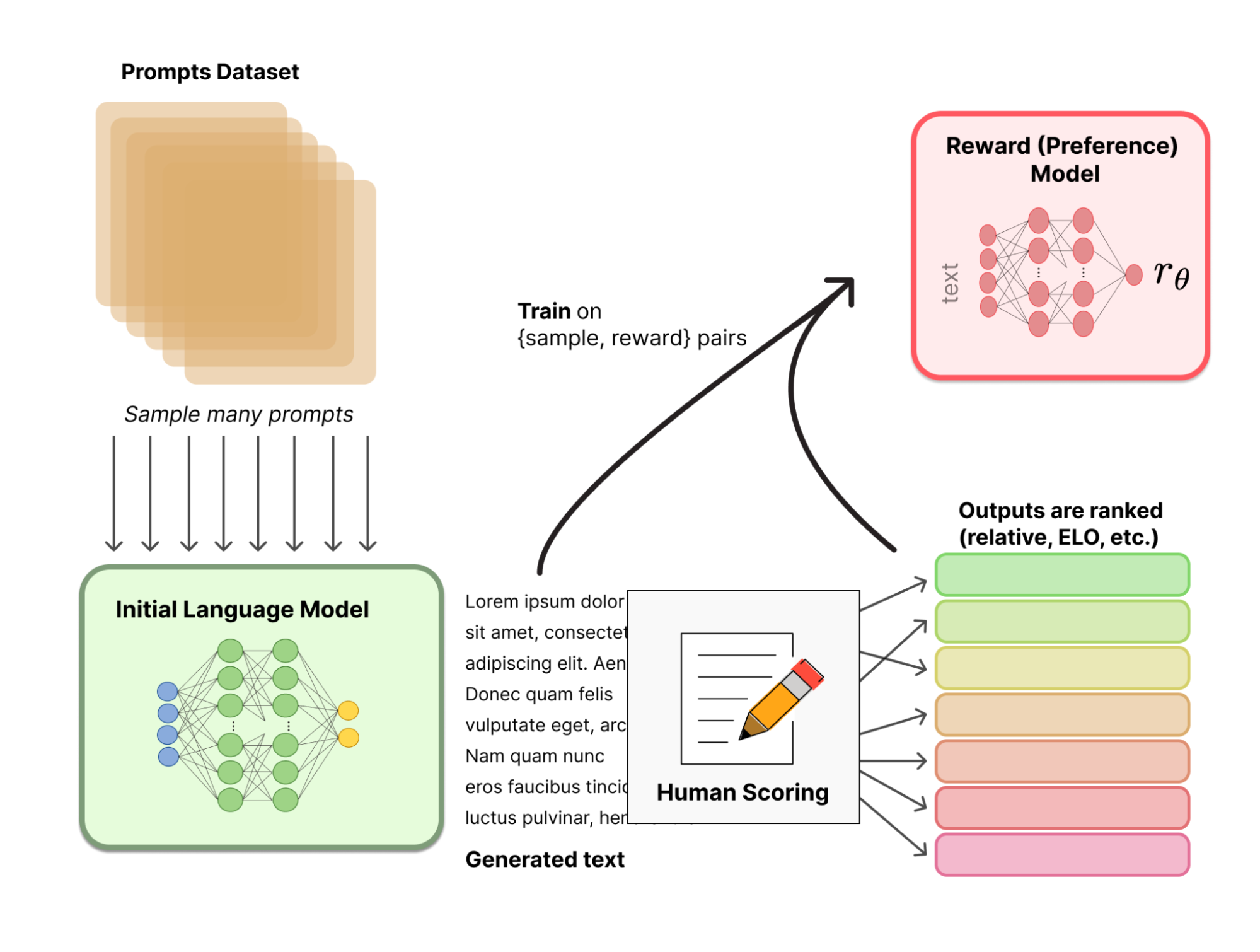
There have been other interesting improvements to training and fine-tuning LLMs such as LoRA. These improvements, most of which are now available as part of HuggingFace’s State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods library, allow to fine-tune LLMs in an efficient way such that the resulting fine-tune model is smaller and more efficient. These approaches are kind of a big deal, because you can turn a huge general-purpose model into a much smaller one that is better at a particular task you are interested in.
Instruction fine tuningPermalink
A specific kind of model fine-tuning is the so-called instruction tuning. Base foundational models like GPT-3 are not very good at following multi-step instructions. However, models that are fine-tuned to instructions like GPT-3.5 (the model used in ChatGPT) are much better. Instructions for fine-tuning can even be generated by the model itself in the so-called self-instruct approach
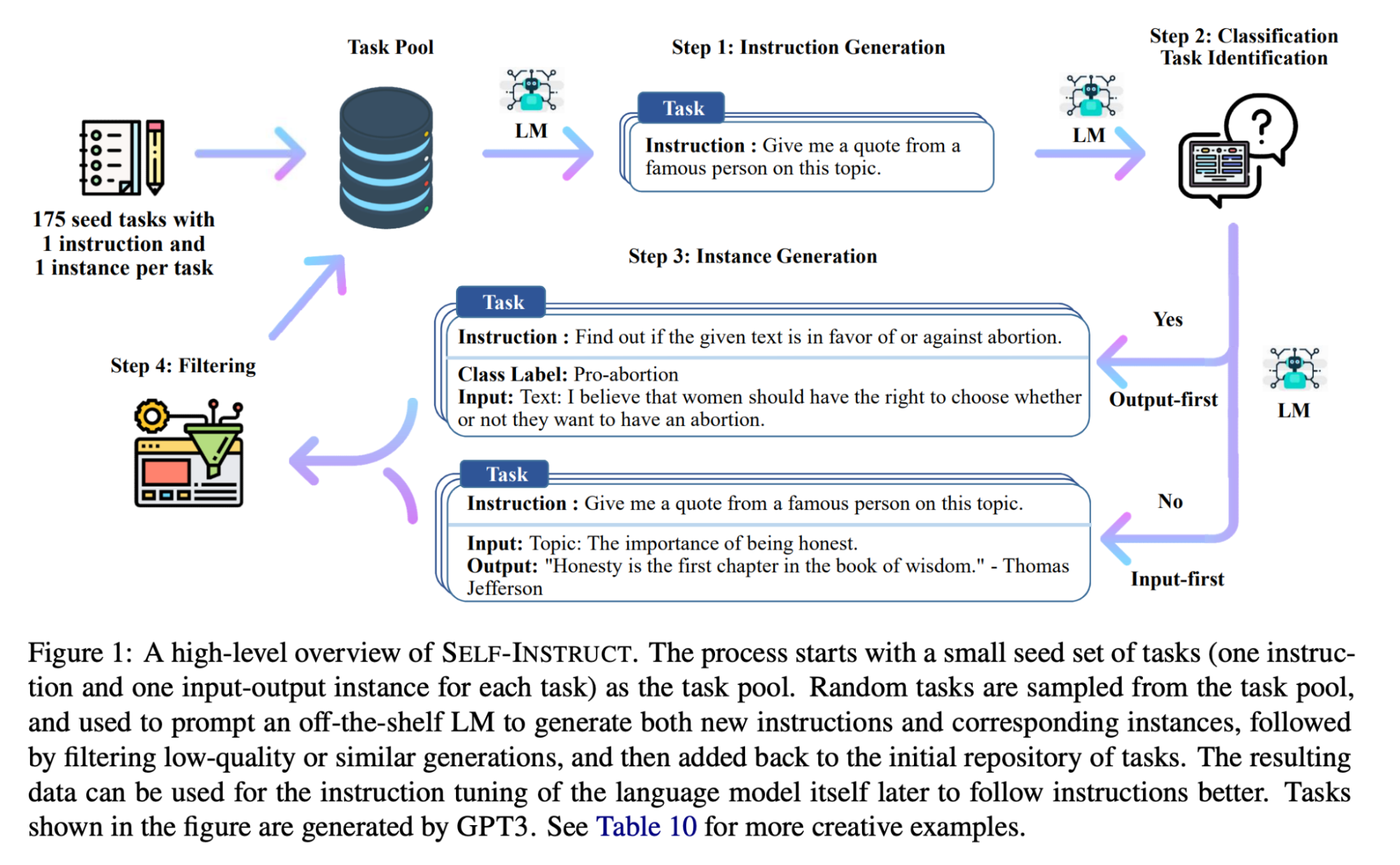
There are several examples of these instruction fine-tuned models available already as open source. For example, Openchatkit is a model fine-tuned for chat from EleutherAI’s GPT-NeoX-20B with over 43 million instructions. Or HuggingFace’s OpenAssistant a Pythia 12B fine-tuned on 22k human demonstrations.
Fine-tuning open source foundation models with data from other modelsPermalink
Ok, so now things are starting to get interesting: it turns out that you can not only get a foundation model and turn it into a better and more efficient model by feeding in instructions, but those instructions you are feeding in can be themselves generated by a model!
And, wait for it, the instructions that you are generating to fine-tune your foundation model do not need to come from an open-sourced model, do they?
Well, meet Stanford’s Alpaca , a “controversial” model that uses LLaMA foundation model from Meta and finetunes with instructions created by OpenAI’s davinci-003.

Alpaca is controversial for two reasons: First, it uses a foundation model LLaMA that is not completely open sourced. LLaMA is only shared with those who follow Meta’s process, and, while model weights leaked soon on 4chan, Meta is not very happy about this. Secondly, it is not clear that OpenAI’s TOS (Terms of Service) allow for this kind of usage. If you own a foundation model, you probably don’t want it to be generating data to train the competition’s model. But, it is not super clear how that can be enforced at this point.
To be fair, Stanford did not release the model weights for Alpaca, and, in fact, soon after removed the model entirely. But, you can imagine that is not the end of it all.
Soon after, a similar GPT4ALL model was released. This model was also a LLaMA model fine-tuned on instructions (using LoRA), this time around from gpt-3.5. The model again faced LlaMA distribution issues, and is now trying to recreate the same results from GPTJ, but I am sure they might try Cerebras-GPT and others soon.
And, just today, we have Vicuna a fine-tune LLaMA on ShareGPT.
On an incredible turn of events, it seems like Google itself was using data generated by ChatGPT to fine tune Bard! According to The Information, a Google engineer resigned over this.

Towards RLAIF and what it means for the future of AIPermalink
So, let’s recap:
- There are pretty capable general purpose foundation models being released every day
- These models can be efficiently fine-tuned on instructions to make them even better
- Those instructions can be generated by other models, including those that are closed source.
Models can improve by learning from each other, and they don’t necessarily need human feedback!
While this is not exactly the same as Reinforcement Learning with AI feedback, I think that we are not very far from this paradigm appearing and dominating much of the landscape. Of course this will introduce a lot of interesting new questions and issues ranging from legal and IP concerns on model owners all the way to propagation of biases and/or errors through generations of models that are trained on each other.
I am not really sure what way this will go, but it is fascinating to see how quickly everything is happening before our eyes. And, while I think the six months moratorium that some are proposing is naive and unrealistic, we really need to think hard about all these fast changes and make sure that we better understand their consequences.