Curai’s mission is to “provide the world’s best healthcare to everyone”. In order to do so, we strive to scale the reach of an individual physician by creating tools that automate large portions of a medical interaction under their supervision. While our end-goal is to provide full end-to-end medical care to everyone, we initially focus on primary care.
Primary care is an essential component of improving healthcare access and outcomes, and its benefits have been shown in many studies. For example, in his 2012 meta study, Leiyu Shi reports that “In both developed and developing countries, primary care has been demonstrated to be associated with enhanced access to healthcare services, better health outcomes, and a decrease in hospitalization and use of emergency department visits. Primary care can also help counteract the negative impact of poor economic conditions on health.” Primary care should be the first and most common touchpoint between patients and the medical system. Primary care is also broad in coverage. This provides a great starting point for scaling through automation.
Recent advances in AI also provide an optimistic outlook for making this mission a reality. We at Curai are convinced that AI and ML will enable significantly better access to and higher quality care. In order to get there, we believe that physicians need technology that helps them operate more efficiently and at a larger scale while also helping them improve quality of care. How do we get started on that?
Our approach to scaling and augmenting physicians is based on the following premises:
- If you want to automate anything, first do it manually.
- Automation should not decrease quality. In fact, it should aspire to improve it.
- The first approach to automating any process should be as simple as possible, yet designed in a flexible way.
- Automation should improve over time.
- Humans in the loop provide quality assurance that helps with (2), and also valuable data that helps with (4).
To accomplish our goals while following the previous premises, we are using a combination of:
- State-of-the-art AI in the wild
- AI with experts-in-the-loop
In the rest of this post, we will describe these two dimensions and the techniques that support them.
State-of-the-art AI in the wild
In order to make a real impact in the world in general and healthcare in particular, AI needs to accomplish two important goals. First, it needs to deliver performance comparable if not better than experts on well understood datasets. But, just as importantly, it needs to be able to operate “in the wild’’ in conditions different from the lab where there might be noise and incomplete information. Our goal is to tackle both these requirements in parallel.
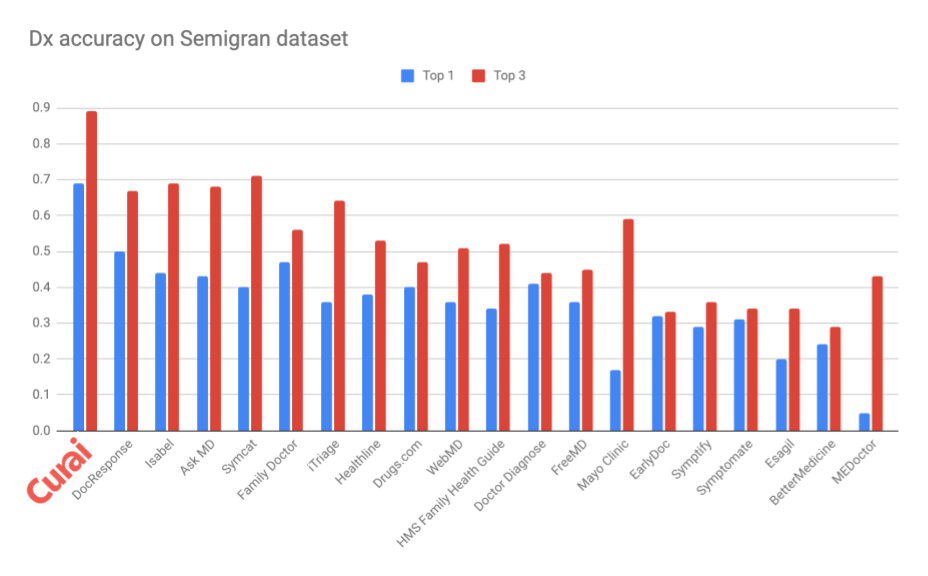
Our models are best-in-class when compared to known competitors. As an example, see our diagnosis accuracy when compared to many online symptom checkers on the benchmark Semigran dataset in the graph below (see “Evaluation of symptom checkers for self diagnosis and triage: audit study”. Semigran et al. 2015). Note how our in-house algorithm beats all of the others in the benchmark significantly both in top-3 and top-1 accuracy. Comparing to other currently existing diagnosis algorithms is hard since most companies are not transparent about the accuracy of their models, and present them only on partially available or fully proprietary datasets. As an example, Raazaki et al. self report on a manually selected subset of Semigran. When extrapolated to the full dataset, this would yield a top-1 accuracy of about 0.46 and a top-3 of 0.65.
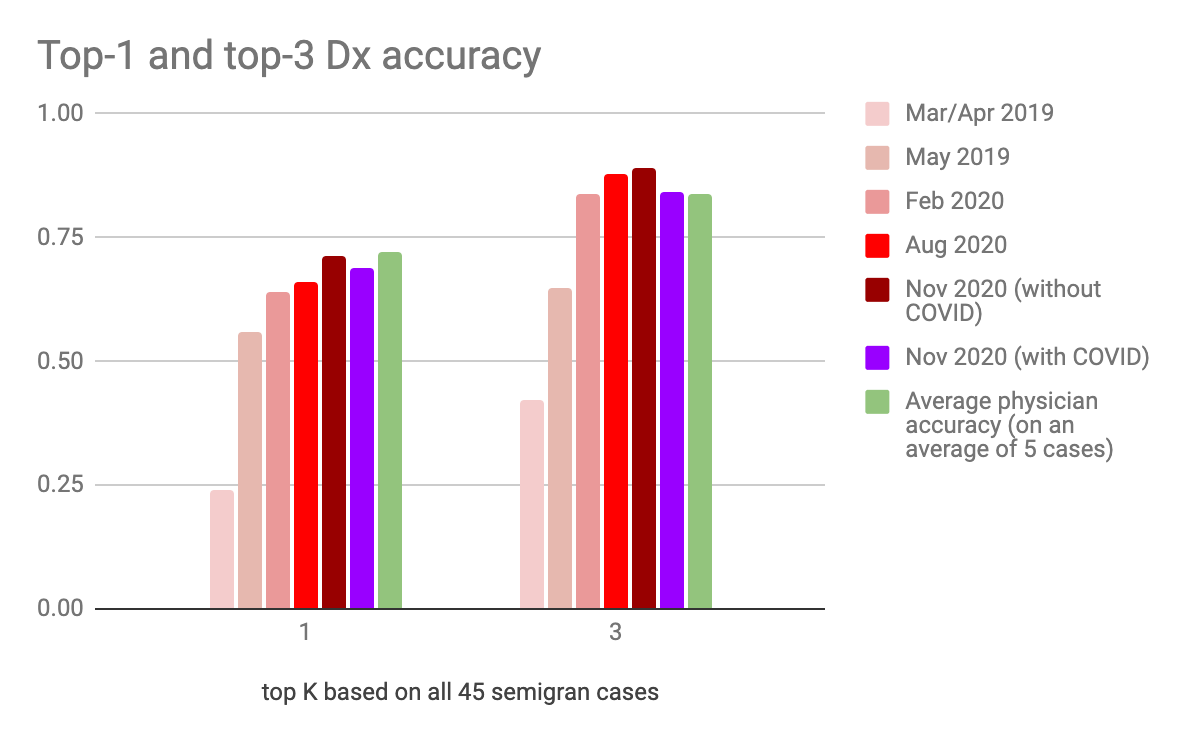
The accuracy of our algorithms improves over time, and some of them are close to the performance of average physicians. See improvement over time and comparison to doctors in the graph below. (Note that the average physician accuracy is derived from “Comparison of Physician and Computer Diagnostic Accuracy” [Semigran et al. 2017] on a small dataset of 234 physicians that decided to diagnose at least one case, as opposed to our AI algorithm that must respond to all cases. Even with that caveat, our Dx algorithm is already surpassing expert physicians on top-3 accuracy). Very importantly, we also include the accuracy of our COVID-aware diagnosis algorithm on pre-existing cases. Even in this situation, our algorithm is delivering close to human doctor accuracies while having quickly adapted to a previously unknown condition (see comparison of with/without COVID from Nov 2020 accuracies). This notion of ever-learning algorithms in the wild is extremely important and contrasts with the approach taken by most existing diagnosis apps for which accuracy not only doesn’t improve, but is likely to get worse over time (see very recent publication at the Journal of Medical Internet Research). Speaking of this very recent publication hot off the press, we just ran the published vignettes through our system and scored 2.5, which is in line with the best system in the study, and well over our competitors.
While Diagnosis (Dx) is definitely a core component of medical practice, there are many other aspects that we are trying to automate with our AI approaches. We focus on the following three medical processes:
- Information gathering
- Assessment/Diagnosis
- Planning
At Curai, we are approaching these problems with a combination of state-of-the art Deep Learning and traditional AI approaches such as expert systems and knowledge bases. Here are some concrete examples of how we are approaching the problems:
- For the Information gathering step we are using a combination of expert systems and NLP in our History Taking algorithm, which is able to surface the optimal medical question to ask given the current differential diagnosis and the findings gathered from the patient so far. These questions are sometimes directly sent to the patient or suggested to the providers as a way to improve their efficacy while also providing feedback to the model.
- For Triaging, Diagnosis, and treatment recommendation, we are using a combination of different approaches. These approaches vary from Deep Learning models learned from EHR to expert systems built in collaboration with top medical institutions in the country.
We have published several peer-reviewed publications on our approaches, and have an assigned patent.
While having public benchmarks and publishable results is important so as to provide some form of comparison with existing approaches, the reality is that diagnosis is not performed in a noise-free environment with perfect information. That is why we also focus on understanding the performance of our algorithms “in the wild”. Once AI is deployed, it needs to observe two important properties:
- Algorithms need to be able to model “the unknown”
- Algorithms need to not only improve over time, but be able to increase their scope and to adapt to new data
We have tackled these two issues since the get go and have designed approaches to modeling “out of band” knowledge and algorithms that can quickly adapt to new/unseen data. For example, in “Open Set Diagnosis”, we show how different out-of-band modeling approaches perform in situations where we have a set of known and unknown conditions in our population. In “Learning from the Experts”, we show how static expert systems can adapt to new conditions by training a deep neural network on a combination of synthetic and natural data. In a recent article, we also show how algorithms can quickly adapt to a rapidly changing situation such as the COVID-19 pandemic.
AI with experts in the loop
Healthcare is made up of many different processes, most of which are medical in nature and therefore require a high level of domain expertise. While those processes have varying degrees of complexity, they can be effectively simplified to an information exchange between a patient and a healthcare professional (i.e. expert) plus access to internal data such as Electronic Health Records (EHR) and external data such as publications, standards, or even lab results.
When trying to automate any of such processes, we always think about keeping physicians in the loop. Just as physicians benefit from the augmentation that AI provides, AI also benefits from keeping experts in the loop, and learning from them. Experts not only provide a safety net for when the AI fails, but also are an essential part of the feedback loop. How is this “expert in the loop” model implemented in practice? In our context, each of the medical processes can be understood as the interaction between patients and our own healthcare professionals through our platform and internal/external data.
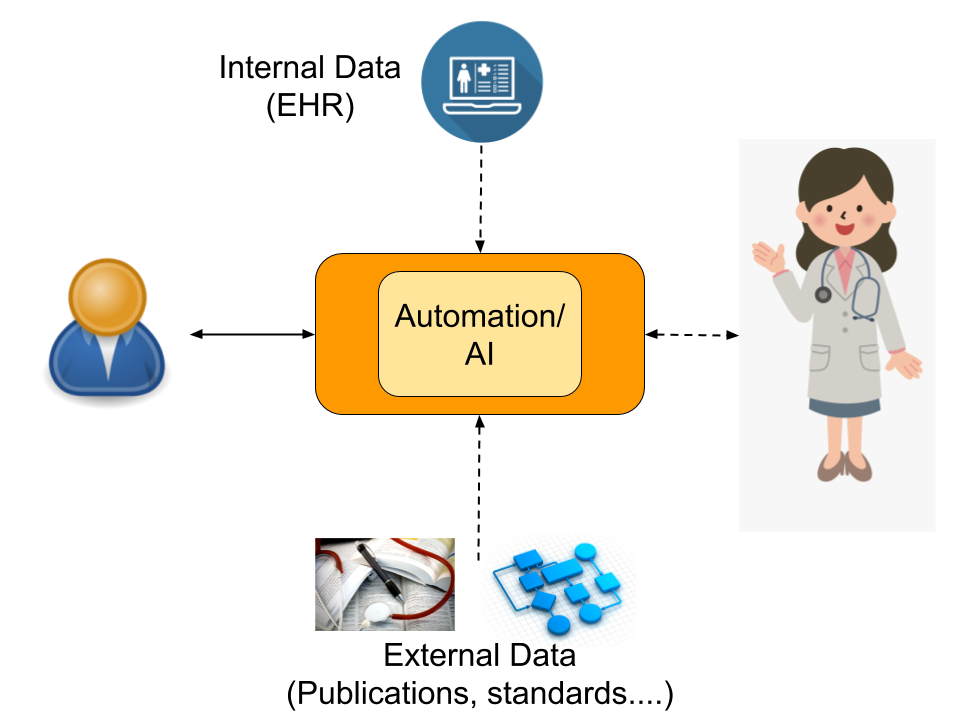
Both patients and physicians interact with the Curai platform to communicate. Physicians also interact with the internal data (mostly our internal Electronic Health Record or EHR, but also our KB, a curated knowledge base that represents medical concepts and the relations between them) and all kinds of external data such as publications, web pages, medical standards, or protocols. For example, when gathering information during the encounter the physician asks the patient questions while interacting with the Curai system. The physician also enters information in the EHR depending on the patient’s answers. And, of course, they solicit information based on their knowledge of medical literature and best practices. Any of those processes can be automated.
In a fully automated system, we would only have interaction between the patient and the Curai system. In a fully automated process, the information gathering step consists of an AI that asks relevant questions to the user based on existing information in the EHR and external knowledge (e.g. protocols). The automated process also fills in relevant information into the EHR. While we do aspire to drive full automation in many parts of the medical encounter, many of our current efforts are currently focusing on driving “partial automation” by keeping experts in the loop.
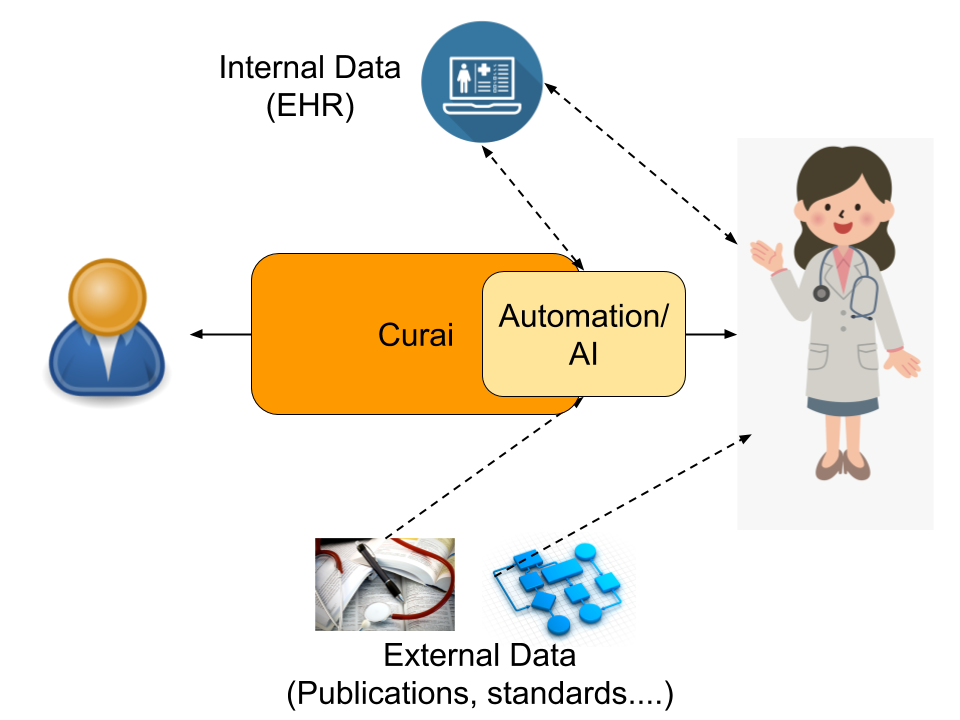
Many of our research efforts focus on automating the interaction between the physician and the system. By automating that interface, we make physicians much more efficient, but also improve quality of care. Examples of projects like these include suggesting questions or responses to physicians, automated charting for improved EHRs, or content/literature recommendation for easier access to external data. Other automation efforts however focus on the interaction between the patient and the system. These include efforts like extracting information from the user reported “reason for encounter”, content recommendation for the user, or automatic routing of the user to the right level of care depending on their input.
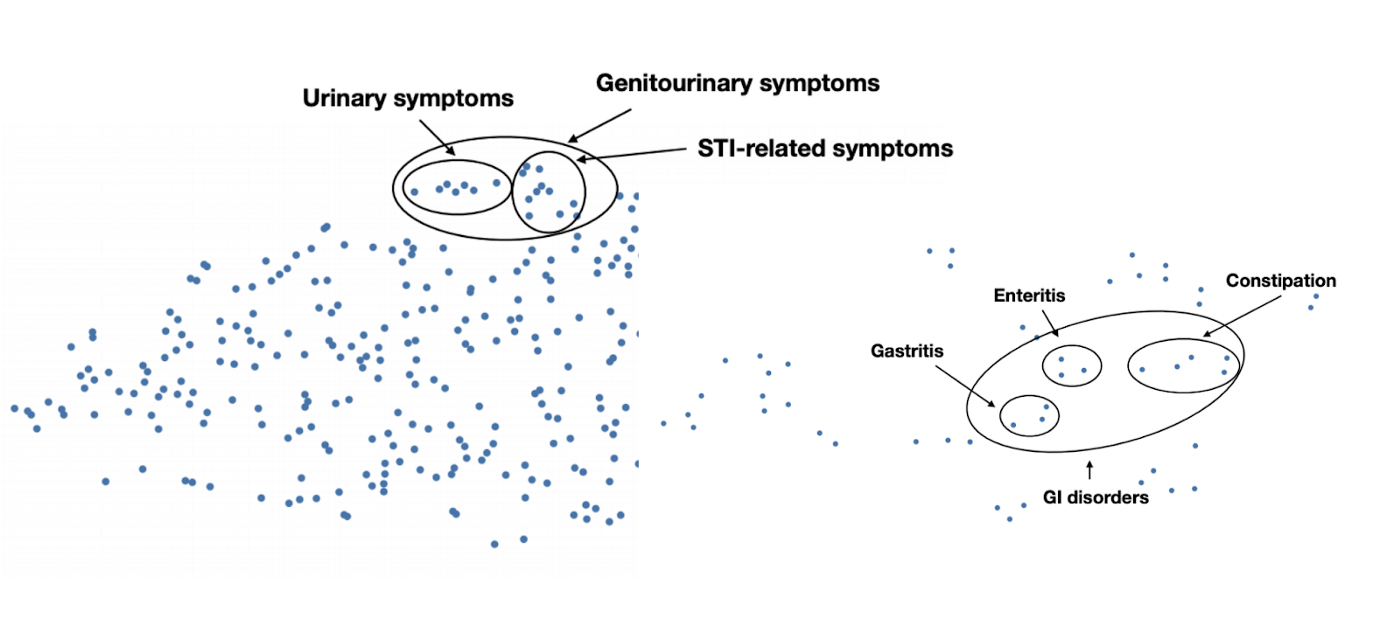
All the ML models we use at Curai are getting validated and retrained thanks to the feedback and the usage we get from our healthcare professionals and our patients. As an example, when we suggest a response to clinical associates and physicians, we record their acceptance, rejection, or modifications. We use that information to improve our models. Our own proprietary data, generated by thousands of conversations between patients and physicians, provides a unique asset from which we can learn medical knowledge. See for example below embeddings learned exclusively from conversations in our product. We have also been able to learn accurate diagnosis models using exclusively conversational data from our users and doctors.
Where are we now, and the road ahead
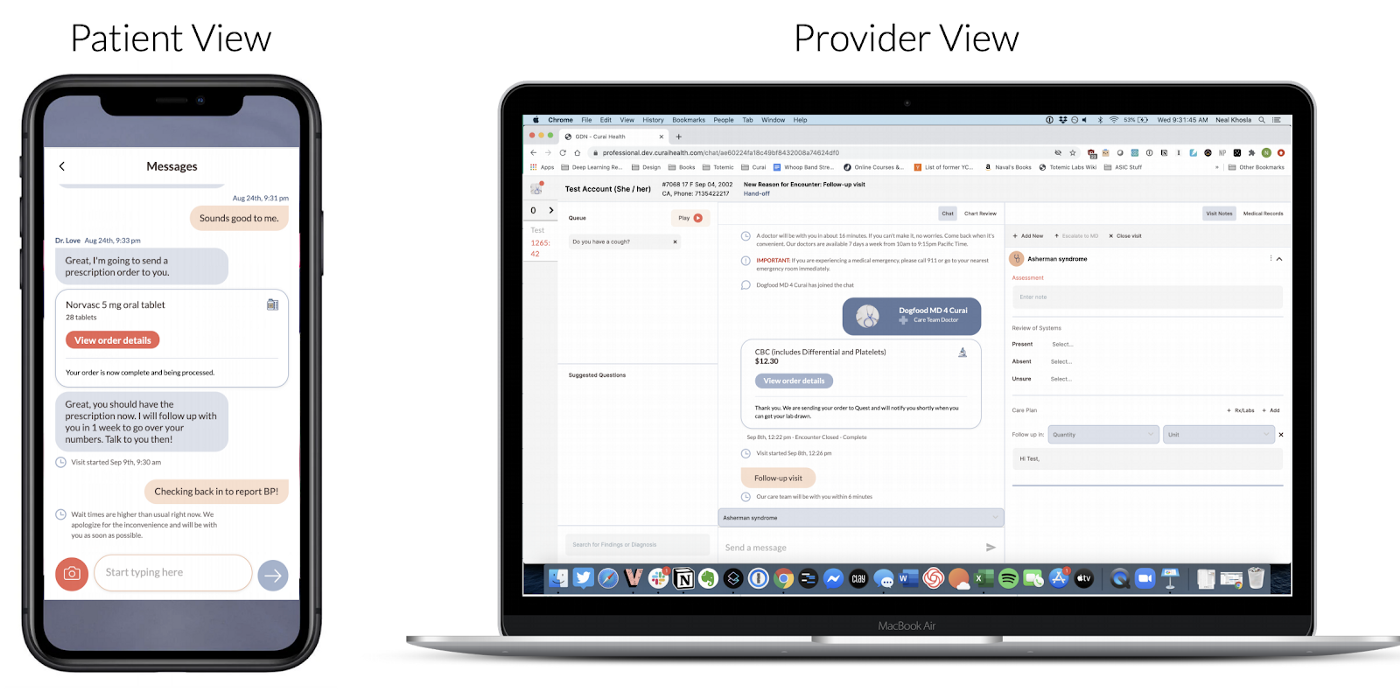
As of today, we are able to automate about 30% of the medical conversation (defined as the percentage of medical findings that make it to the EHR and are automatically generated by the system). However, the improvement we are seeing while integrating automation features both on the Patient and Provider Clients (see below) gives us confidence that we will be able to get that number close to 80–90% in the near future. In order to do so, we need to expand our current product features to include other modalities and inputs as well as tackle other processes in the medical workflow. Our research efforts are already underway and we hope to soon include many of those results in the product itself.
The road towards full automation includes two phases: (1) Automate only high incidence conditions, (2) Broaden the scope of the automation to cover 80–90% of primary care. Focusing on high-incidence conditions (e.g. common cold or UTI) makes sense for several reasons. For one, we want to focus first on automating those conditions that will have more impact on our ability to scale. Also, those conditions are the ones we get more data on, and therefore where the learning loop is able to quickly improve over the baseline. Note though that this automation is designed in a generalizable way so that we can expand the automation coverage easily over time.
Automation, understood as a way to augment and scale physicians, is a fundamental hypothesis of our approach to radically improving healthcare access and quality. We believe in a world where people will have access to high quality medical advice and care 24/7 on their phones, and we at Curai are determined to make this happen soon.