A couple of days ago, I attended the Analytics @Webscale workshop at Facebook. I found this workshop to be very interesting from a technical perspective. This conference was mostly organized by Facebook Engineering, but they invited LinkedIn, and Twitter to present, and the result was pretty balanced. I think the presentations, though biased to what the 3 “Social Giants” do, were a good summary of many of the problems webscale companies face when dealing with Big Data. It is interesting to see how similar problems can be solved in different ways. I recently described how we address at Netflix many of these issues in our Netflix Techblog. It is also interesting to see how much sharing and interaction there is nowadays in the infrastructure space, with companies releasing most of what they do as open source, and using – and even building upon – what their main business competitors have created. These are my barely edited notes:
Twitter presented several components in their infrastructure. They use Thrift on HDFS to store their logs. They have now build Twitter Parquet, a columnar storage database that improves storage efficiency by allowing to read columns at a time.
 |
|---|
| @squarecog talking about Parquet |
They also presented their DAL (Data Access Layer), built on top of HCatalog.
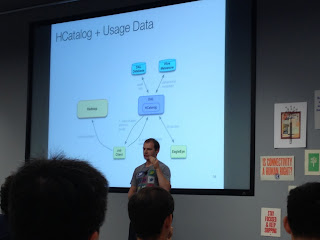 |
 |
Of course, they also talked about Twitter Storm, which is their approach to distributed/nearline computation. Every time I hear about Storm it sounds better. Storm now supports different parts of their production algorithms. For example, the ranking and scoring of tweets for real-time search is based on a Storm topology.
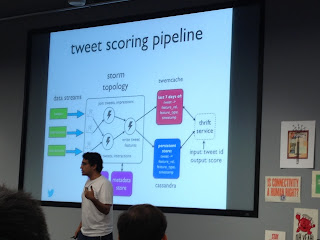 |
Finally, they also presented a new tool called Summingbird. This is still not open sourced, but they are planning on doing so soon. Summingbird is a DSL on top of Scalding that allows to define workflows that integrate offline batch processing from Hadoop and near-line from Storm.
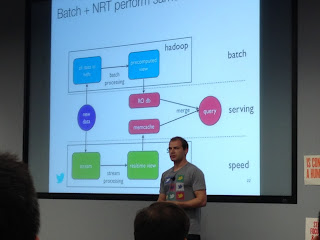 |
 |
LinkedIn also talked about their approach to combining offline/near-line/real-time computation although I always get the sense that they are much more leaning towards the former. They talked about three main tools: Kafka, their publish subscribe system; Azkaban, a batch job scheduler we have talked about using in the past; and Espresso a timeline-consistent NOSQL database.
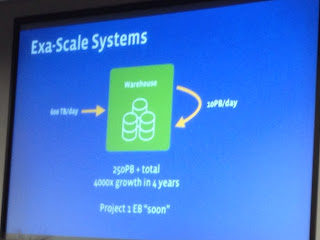 |
Facebook also presented their whole stack. Some known tools, some not so much. Facebook Scuba is a distributed in-memory stats store that allows them to read distributed logs and query them fast. Facebook Presto was a new tool presented as the solution to get fast queries out of Exabyte-scale data stores. The sentence “A good day for me is when I can run 6 Hive queries” supposedly attributed to a FB data scientist stuck in my mind ;-).
Morse is a different distributed approach to fast in-memory data loading. And, Puma/ptail is a different approach to “tailing” logs, in this case into HBase.
 |
Another Facebook tool that was mentioned by all three companies is Giraph. (To be fair, Giraph was started at Yahoo, but Facebook hired the creator Avery Ching). Giraph is a graph-based distributed computation framework that works on top of Hadoop. Facebook claims they ran a Page Rank on a graph with a trillion edges on 200 machines in less than 6 minutes/iteration. Giraph is another alternative to Graphlab. Both LinkedIn and Twitter are using it. In the case of Twitter, it is interesting to hear that they now prefer it to their own in-house (although single-node) Cassovary. It will be interesting to see all these graph processing tolls side by side in this year’s Graphlab workshop.
Another interesting thread I heard from different speakers as well as coffee-break discussions was the use of Mesos vs. Yarn or even Spark. It is clear that many of us are looking forward to the NextGen Mapreduce tools to reach some level of maturity.